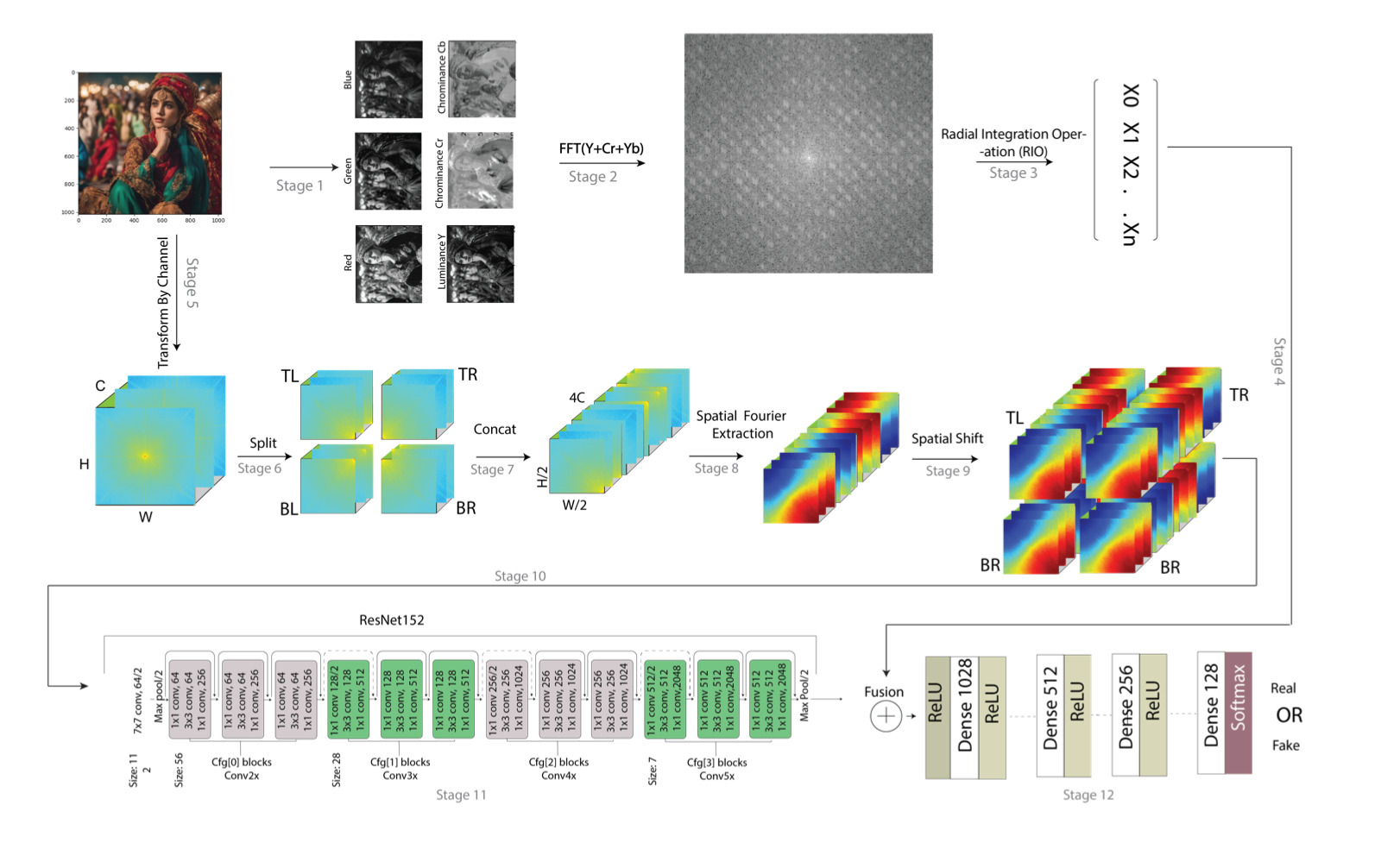
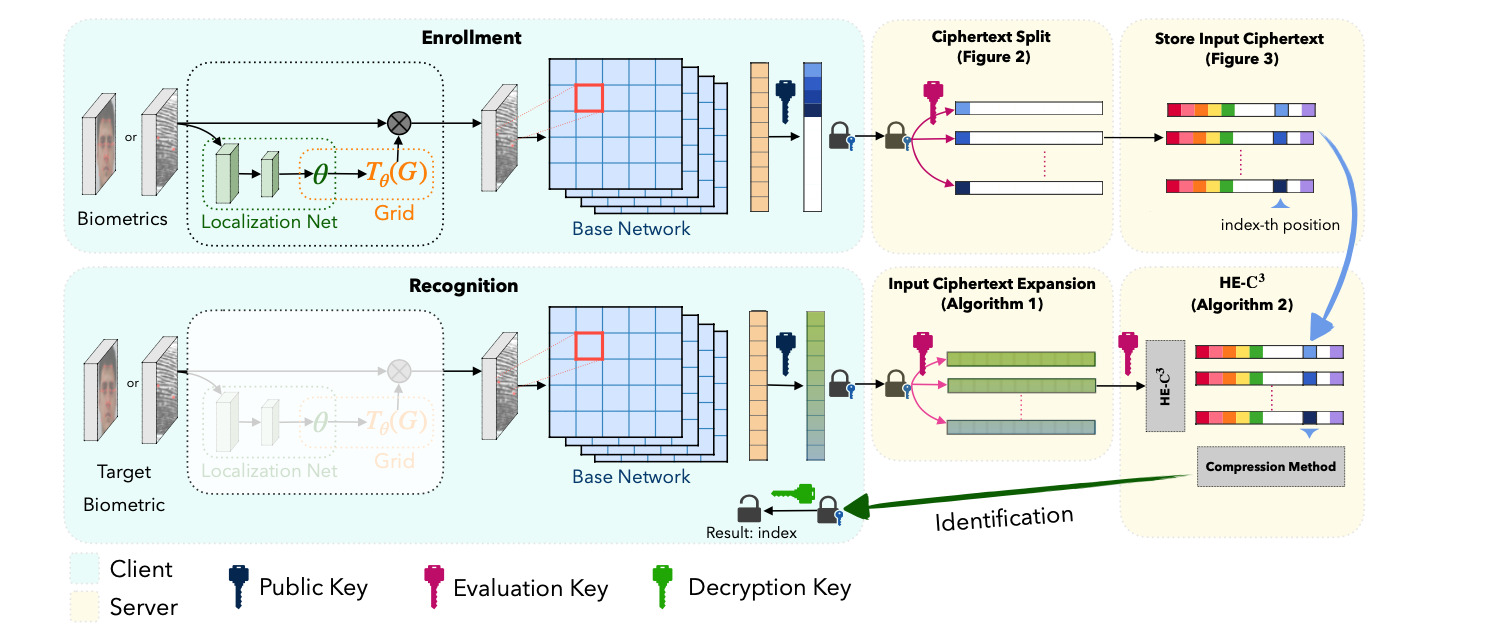
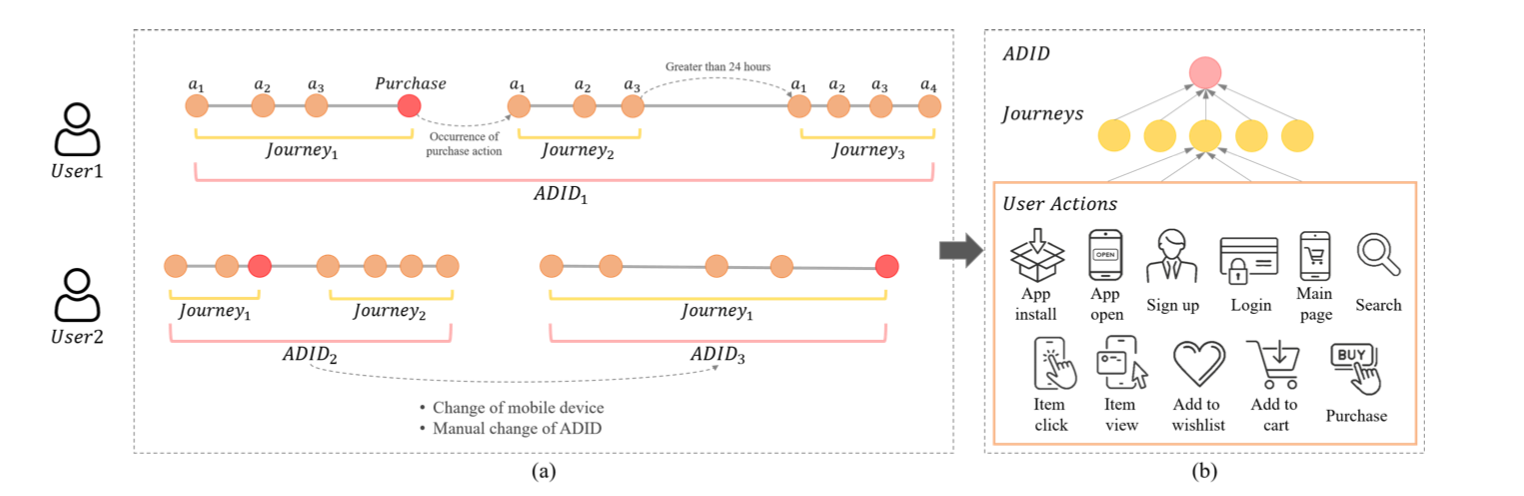
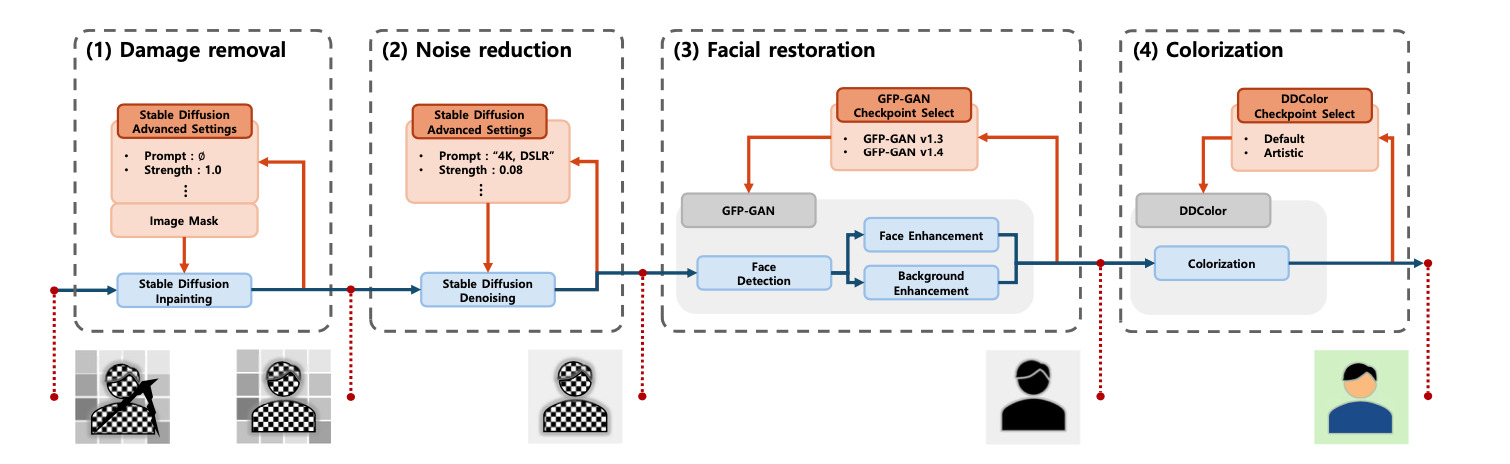
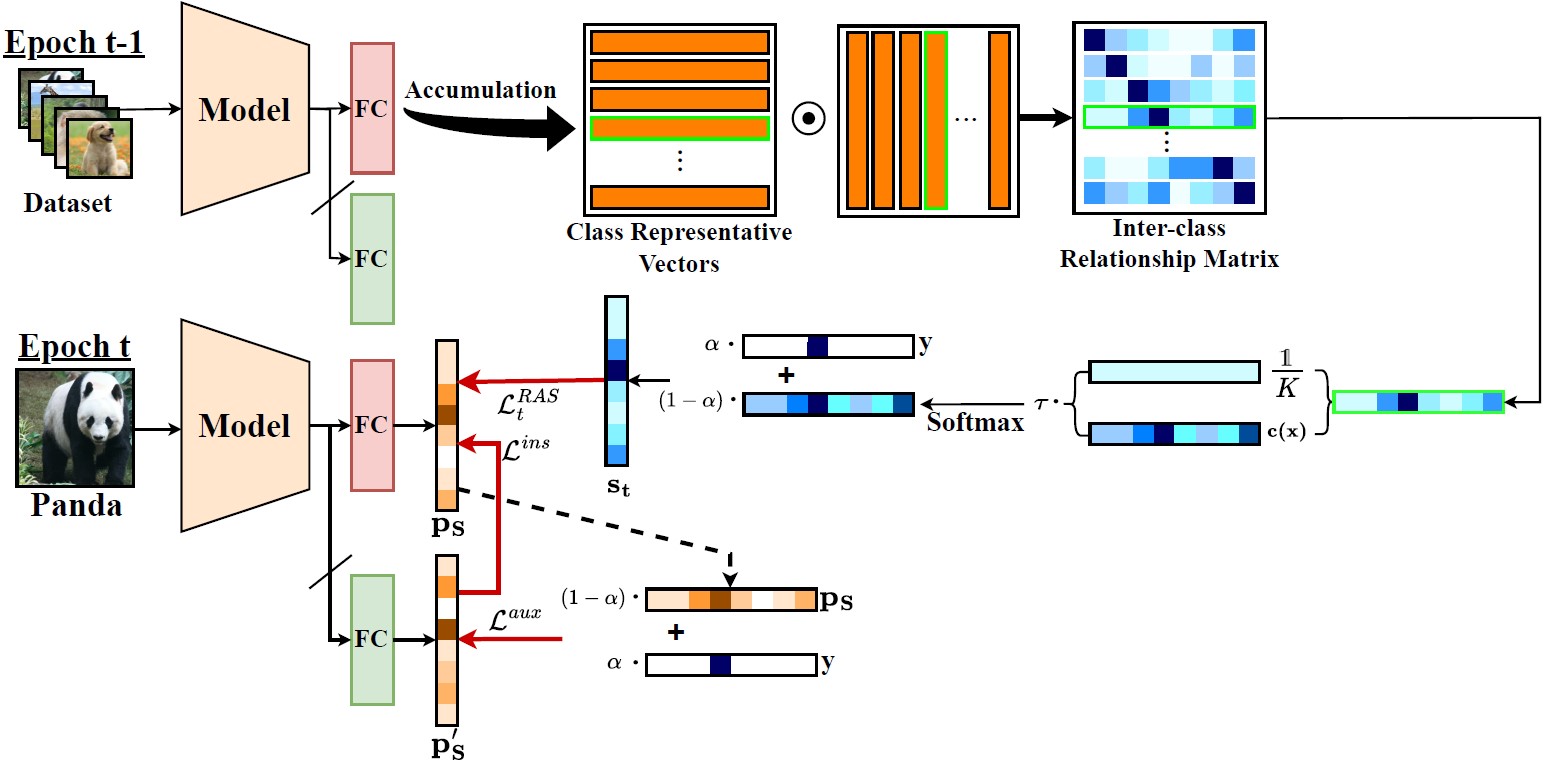
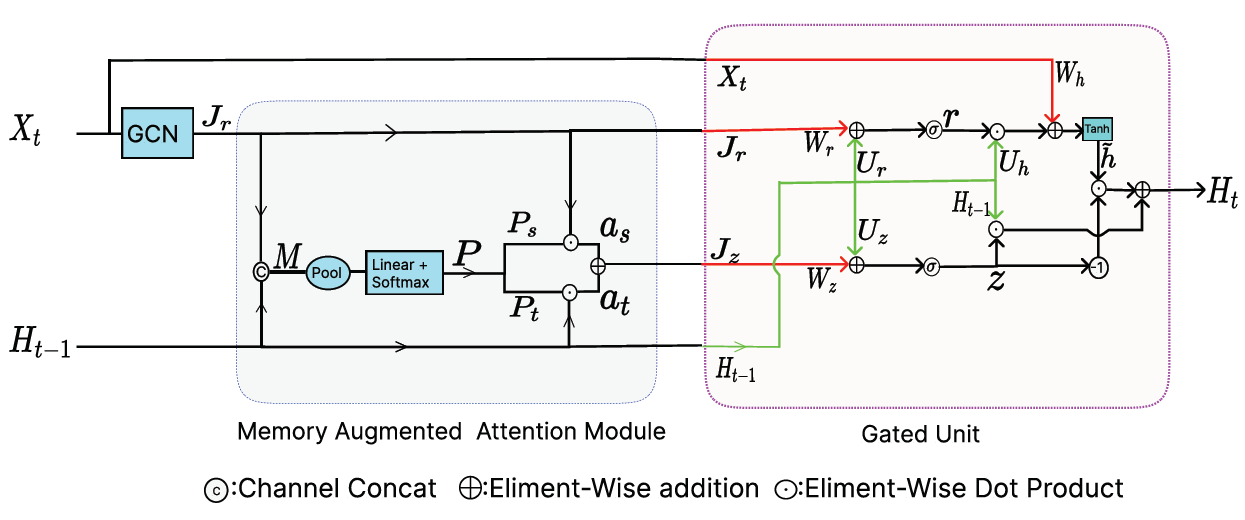
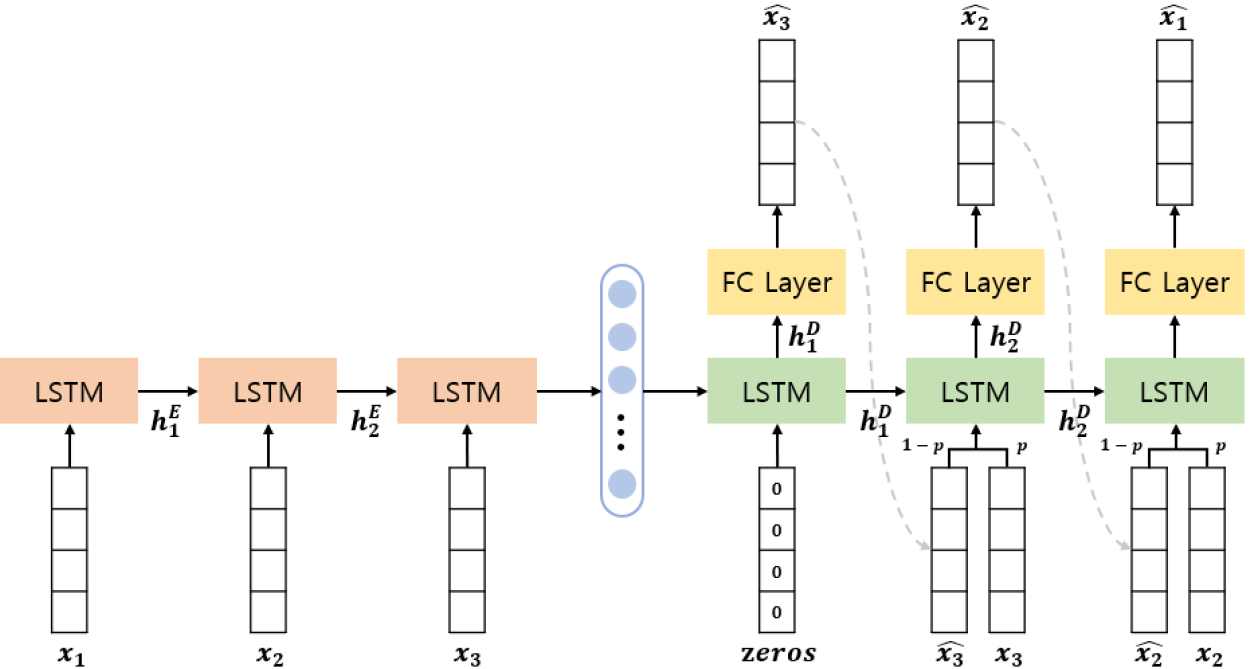
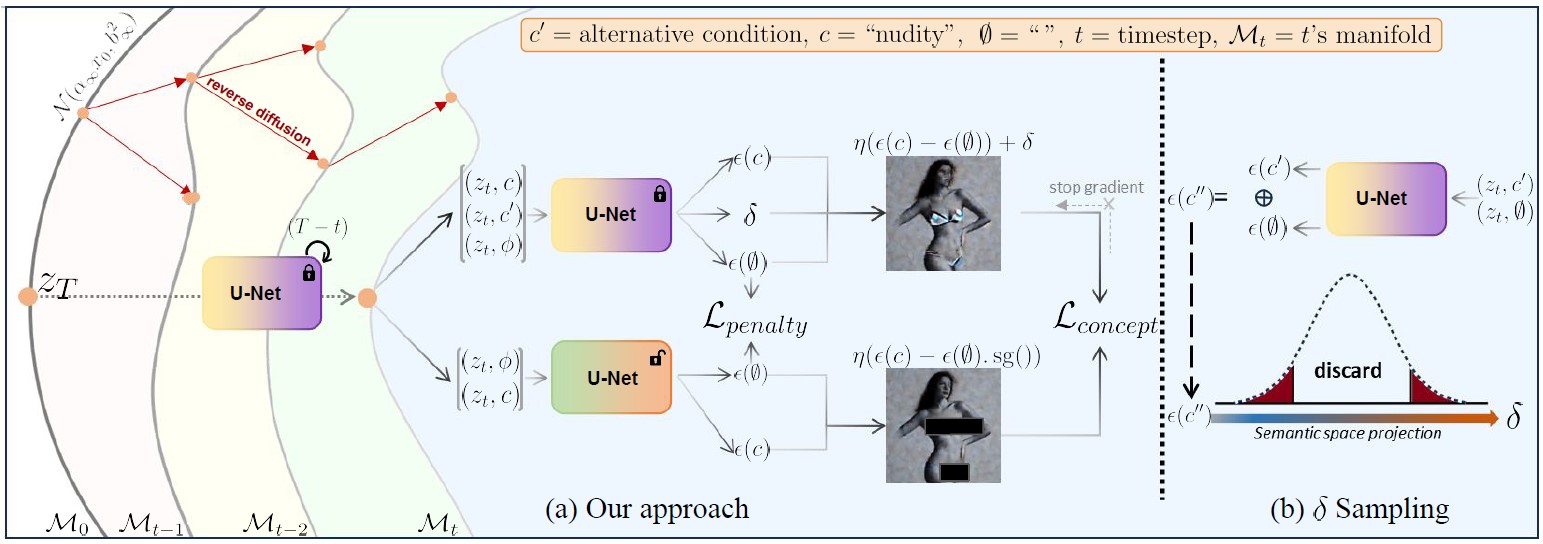
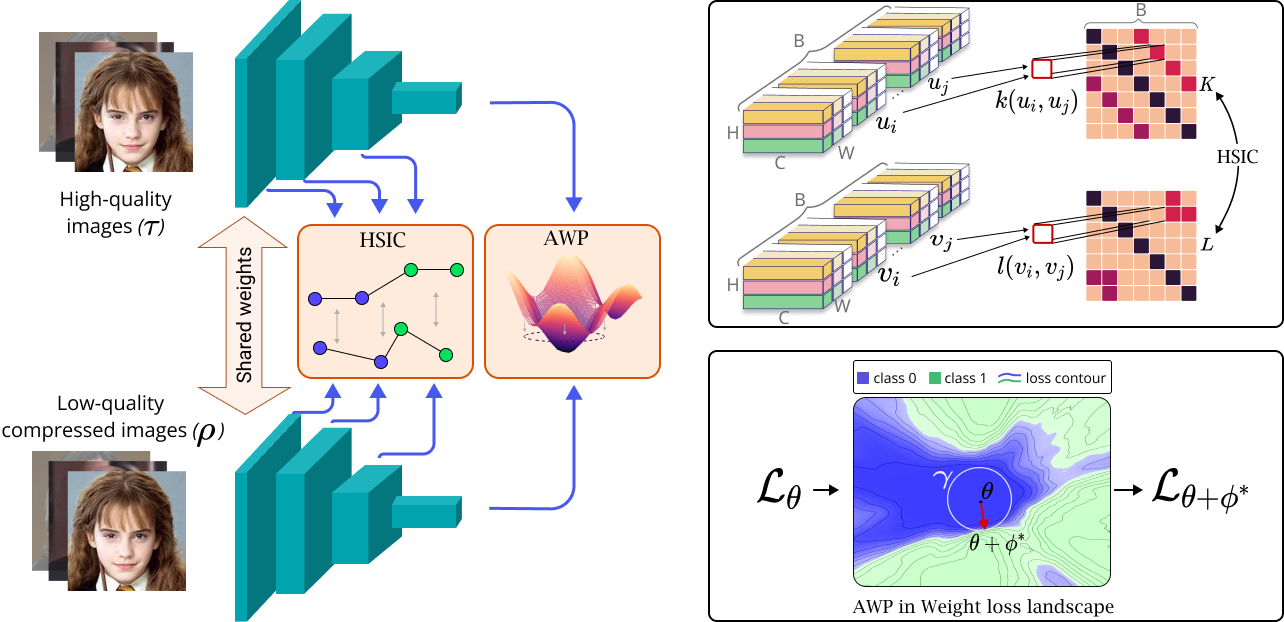
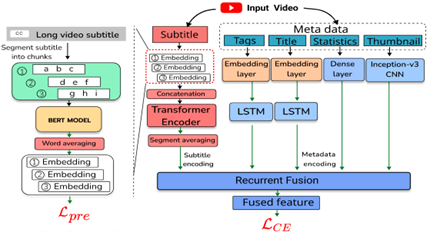
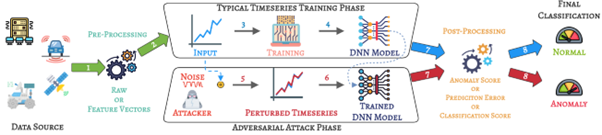
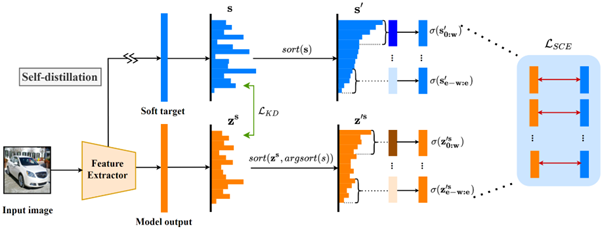
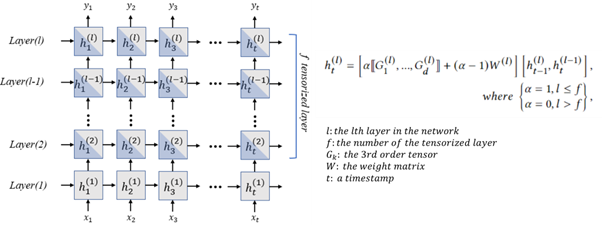
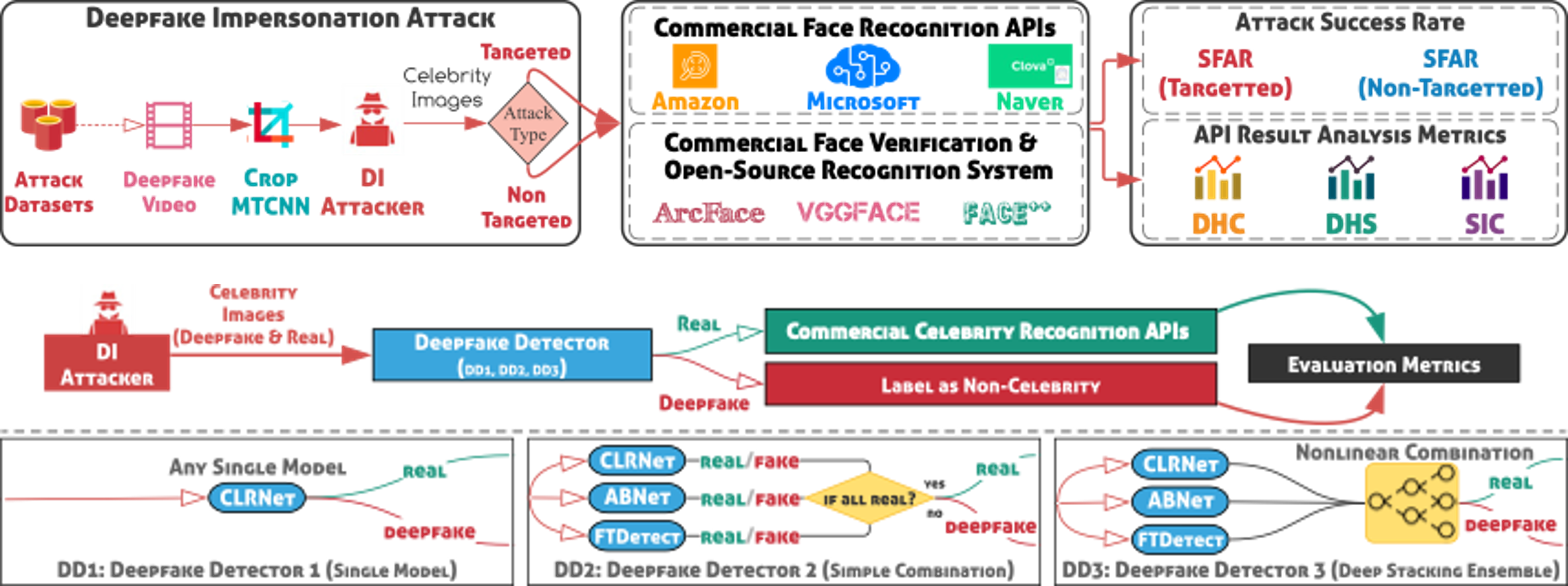
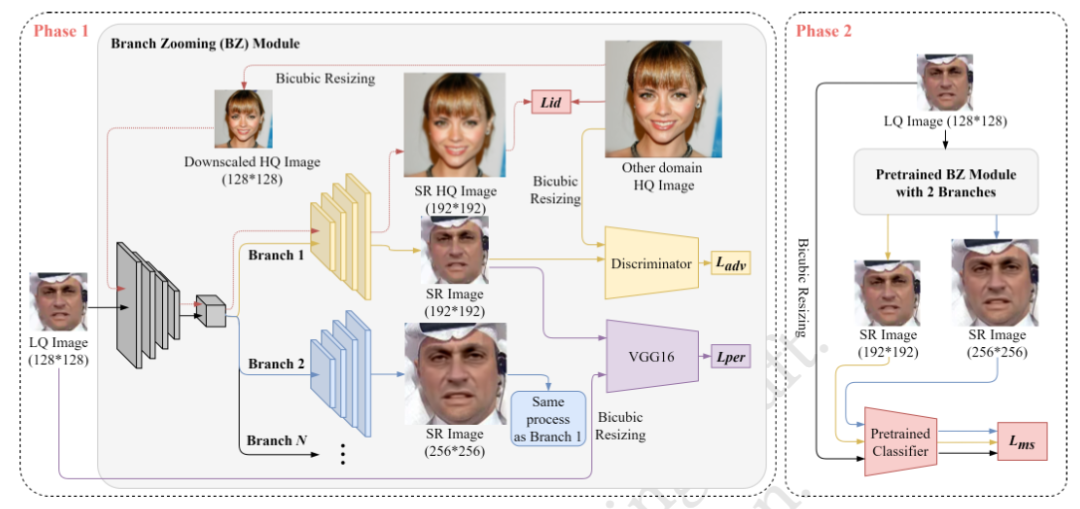
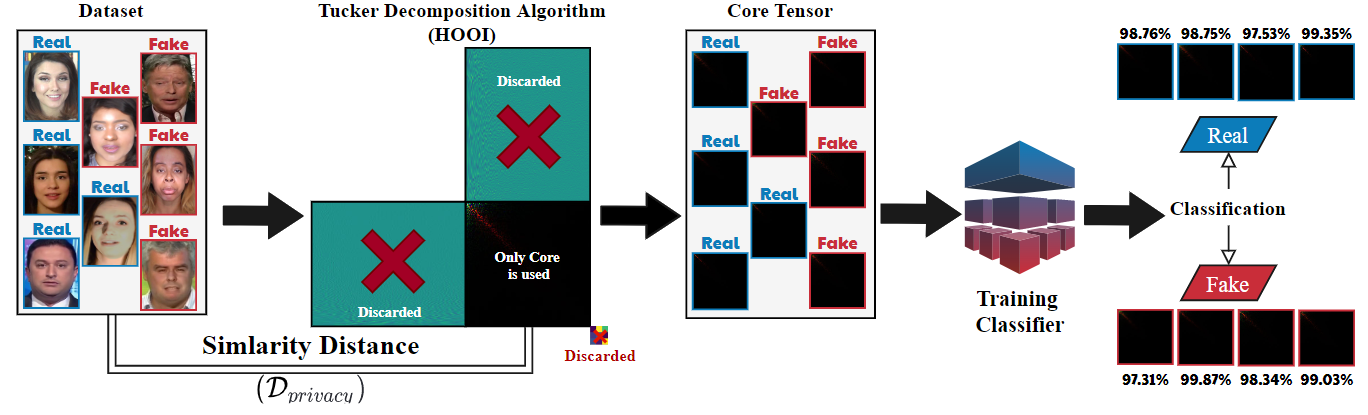
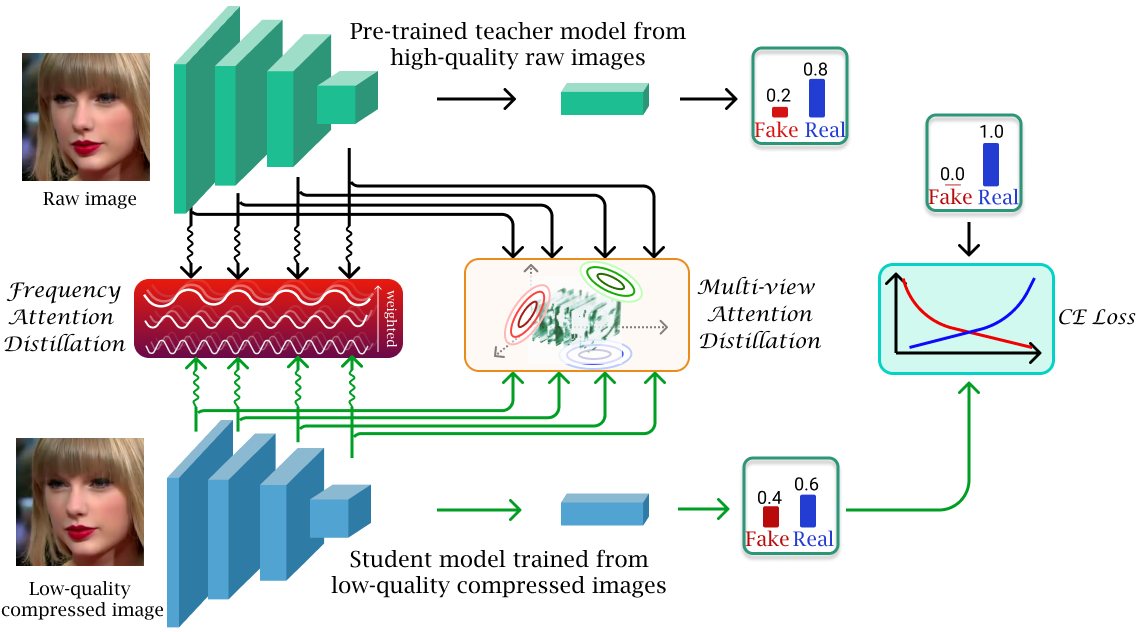
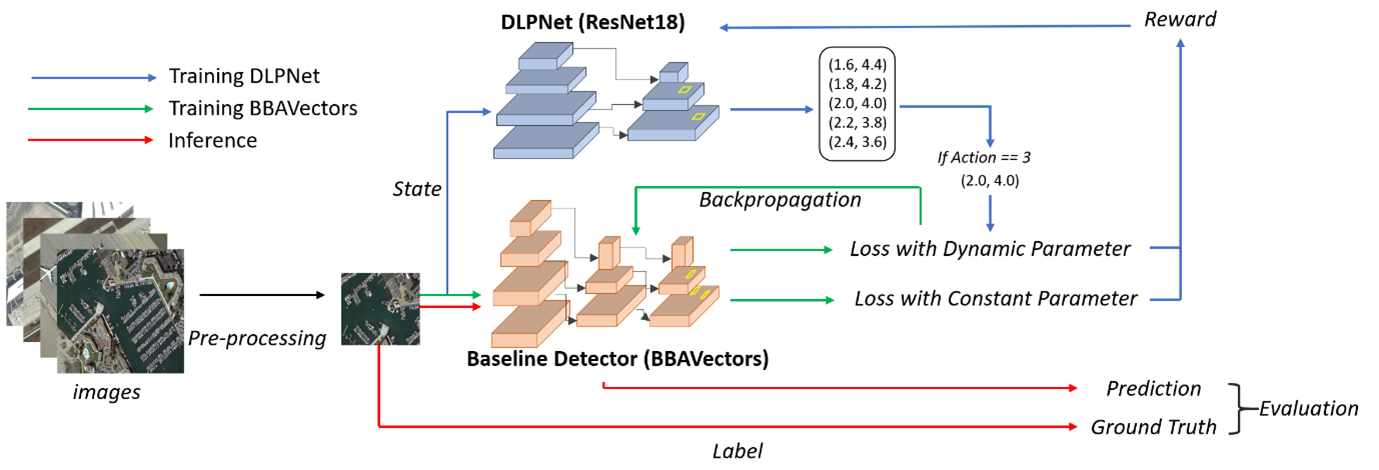
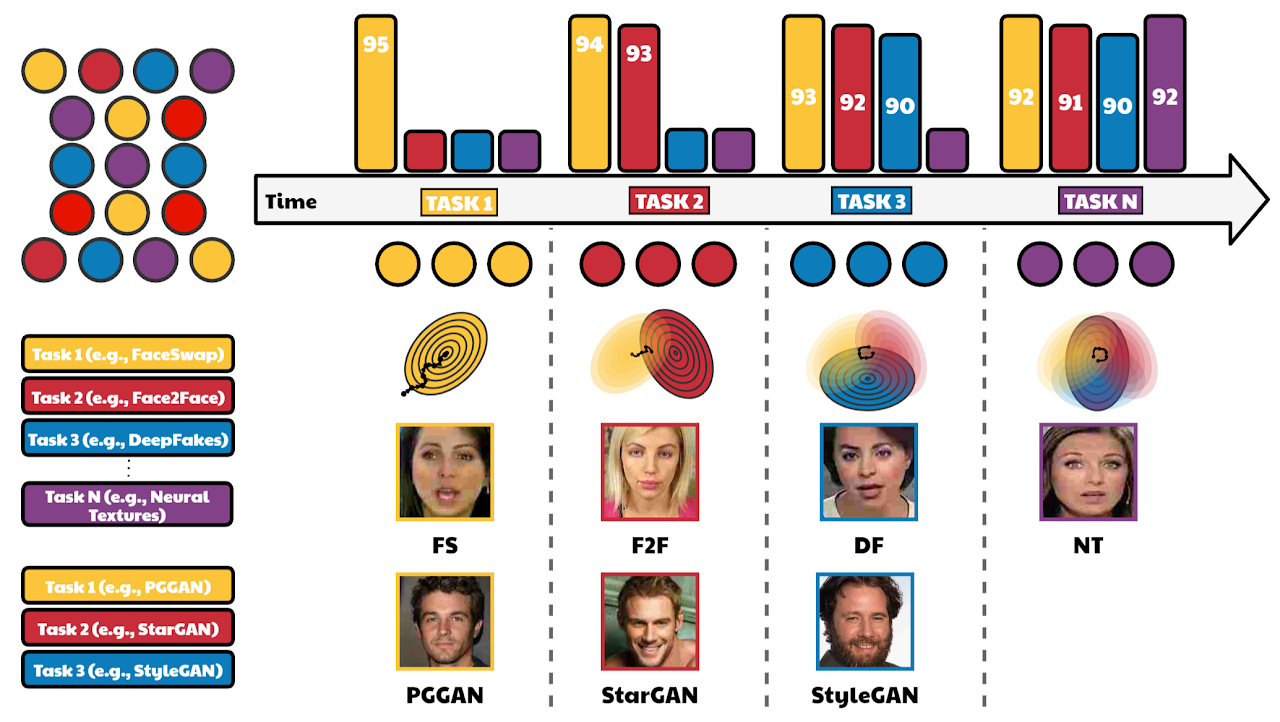
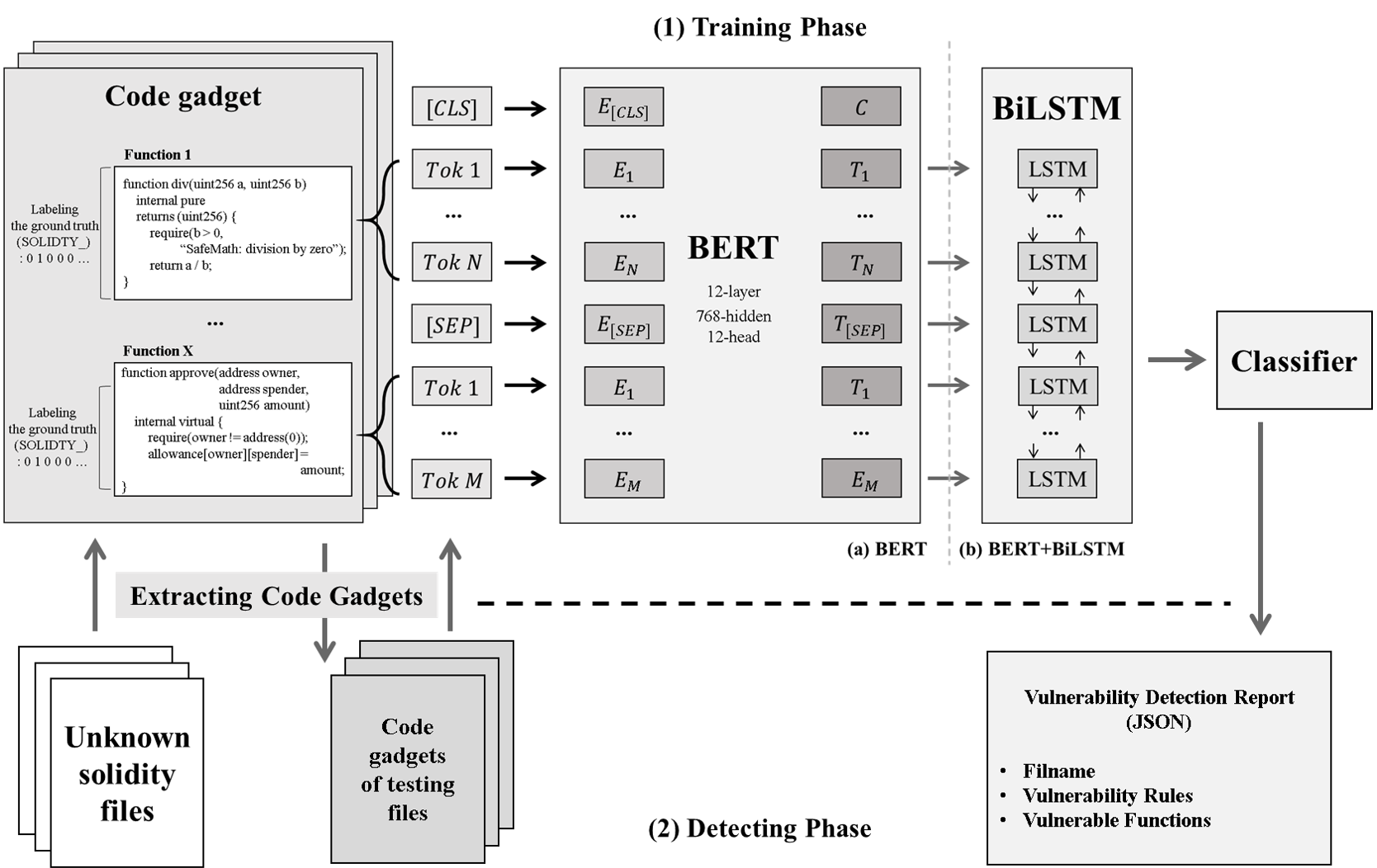
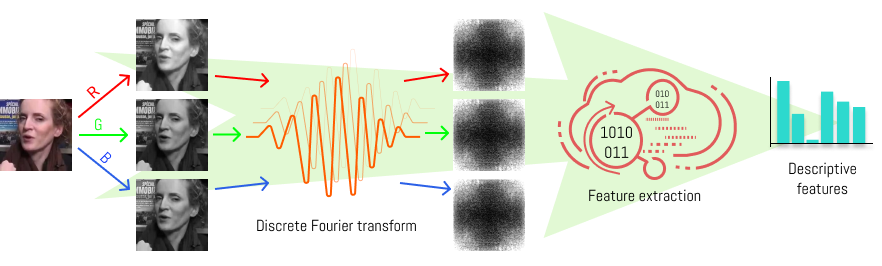
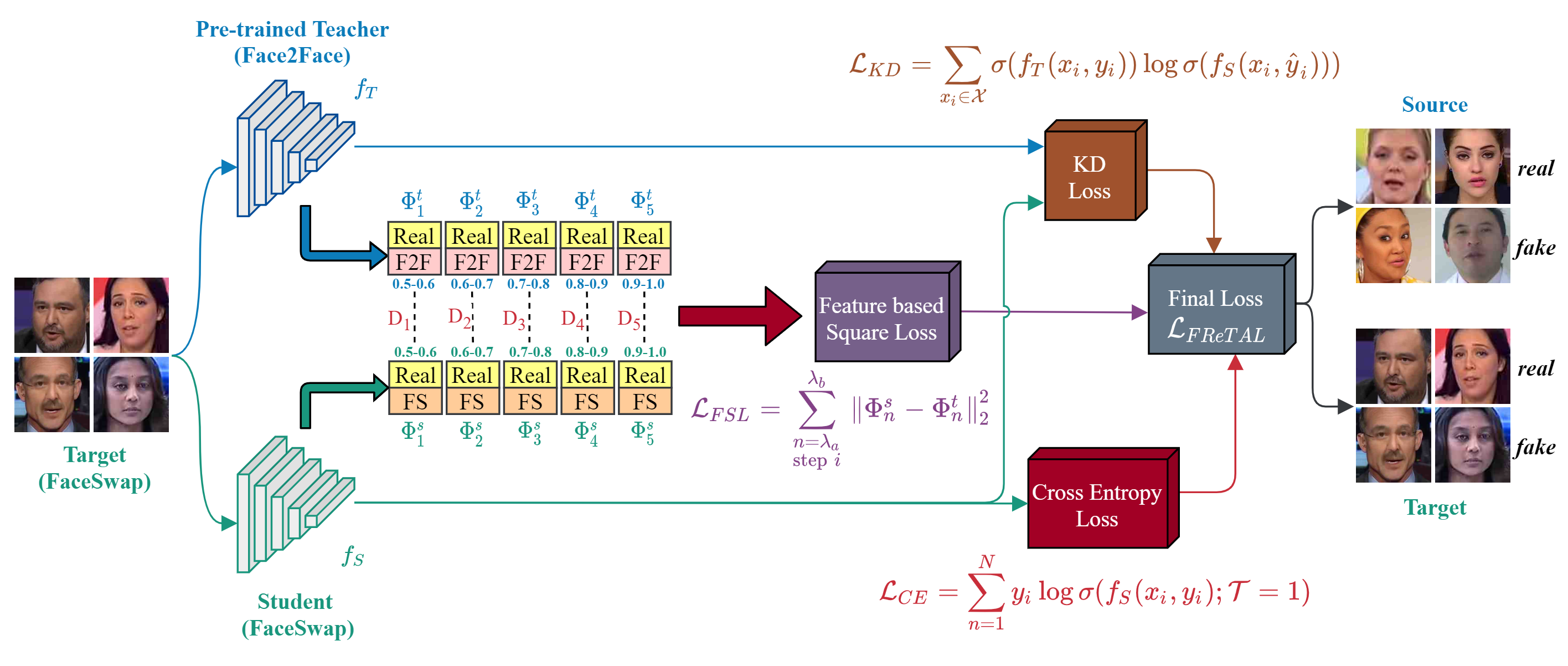
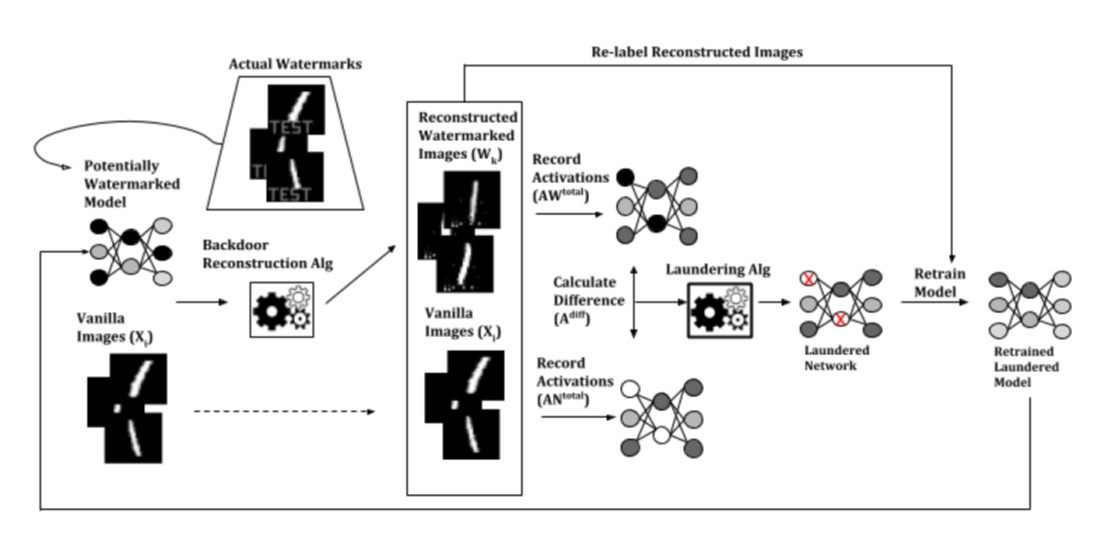
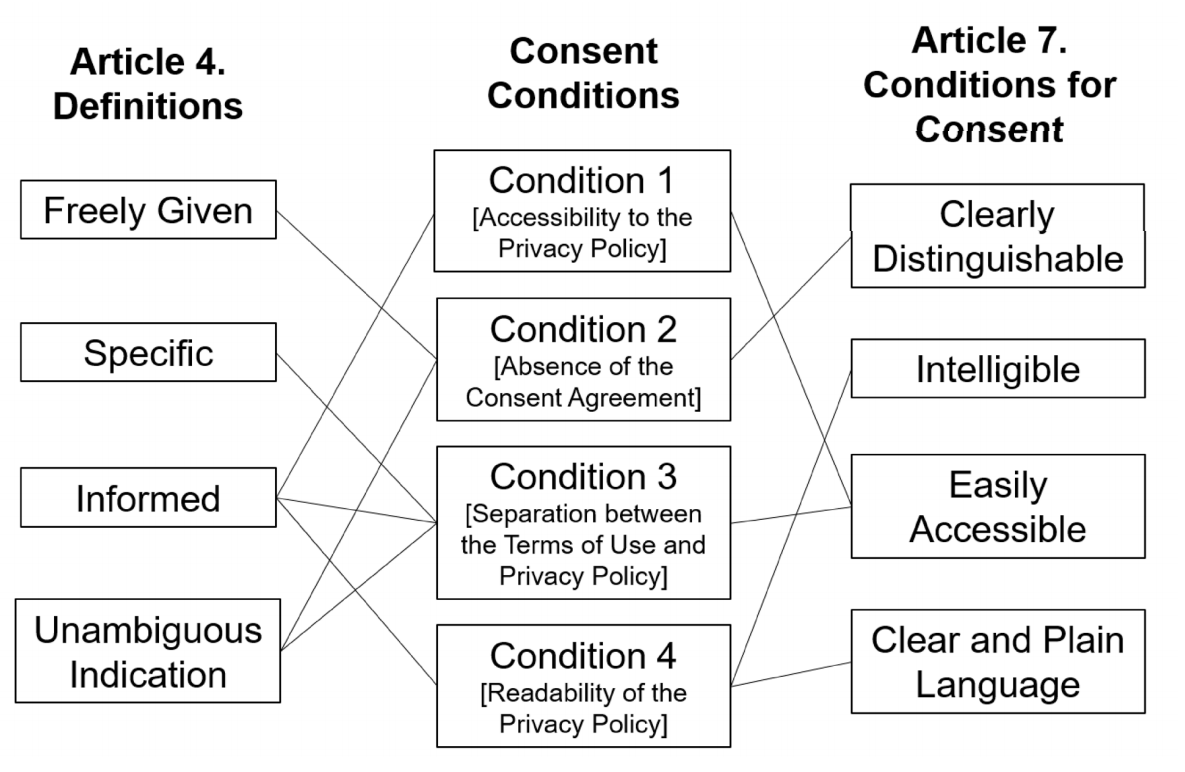
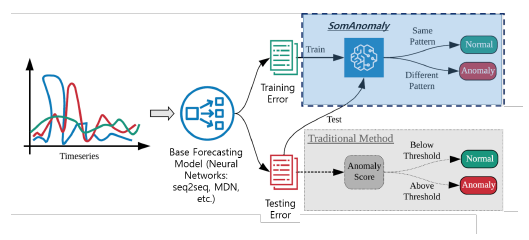
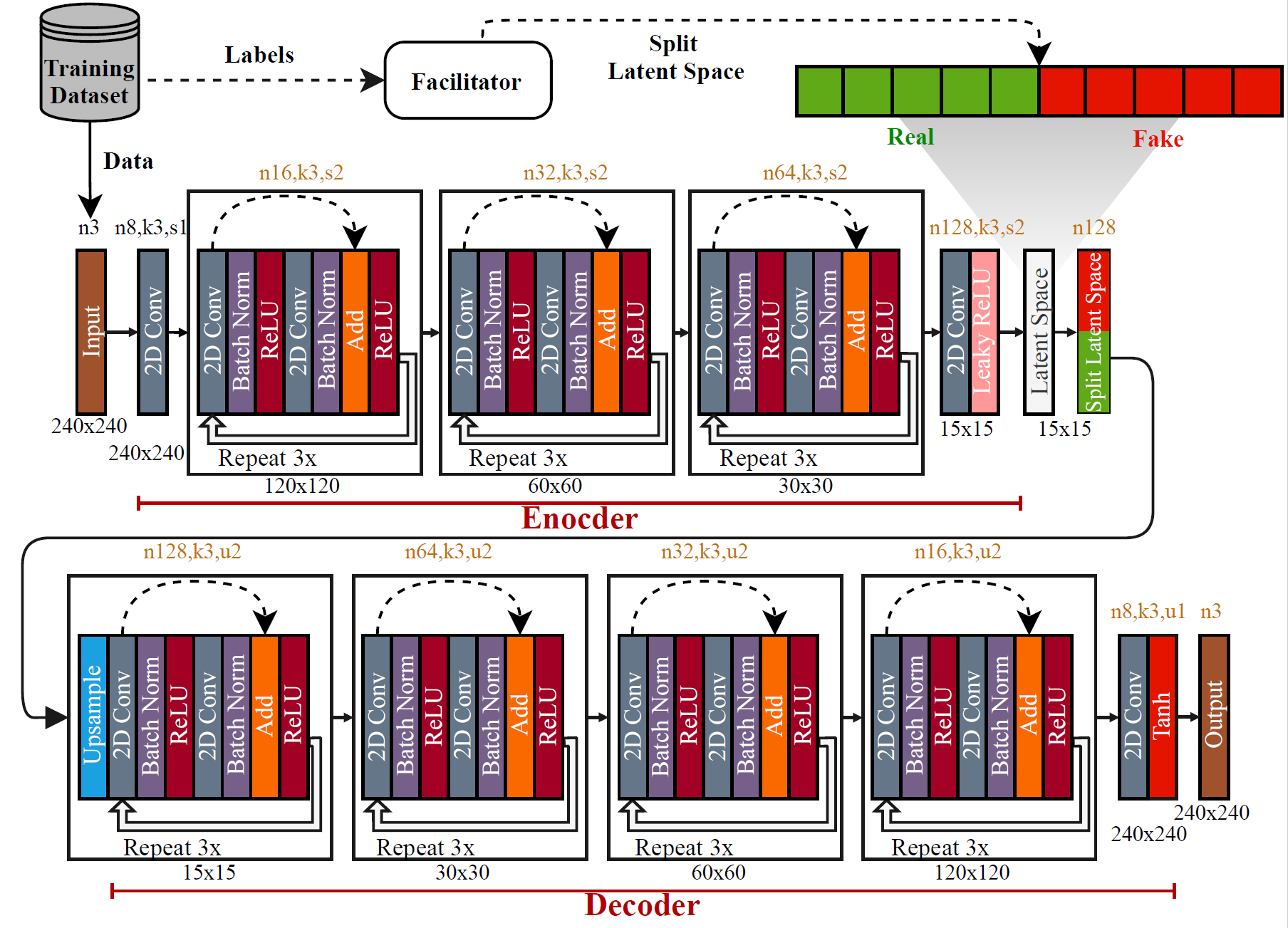
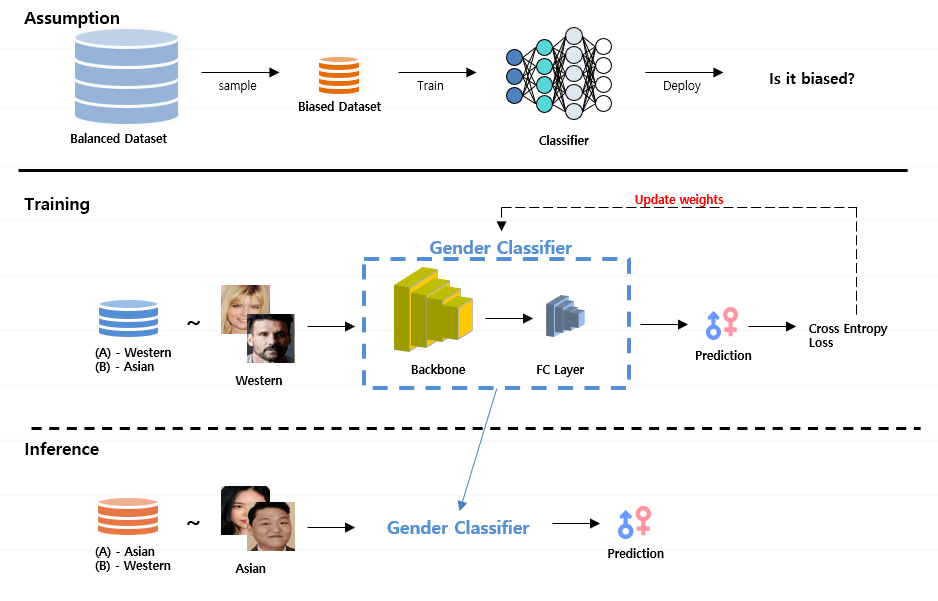
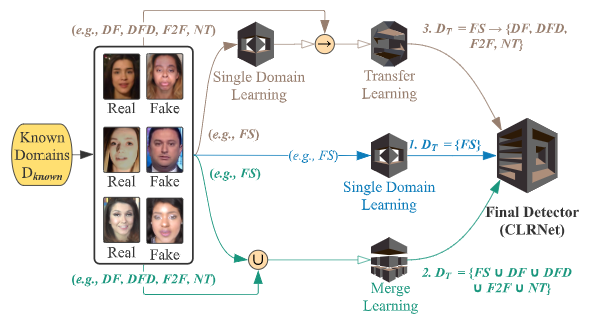
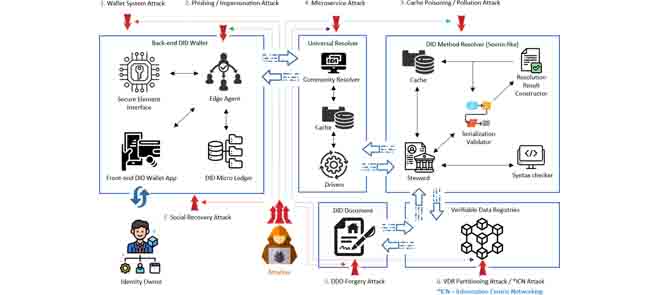
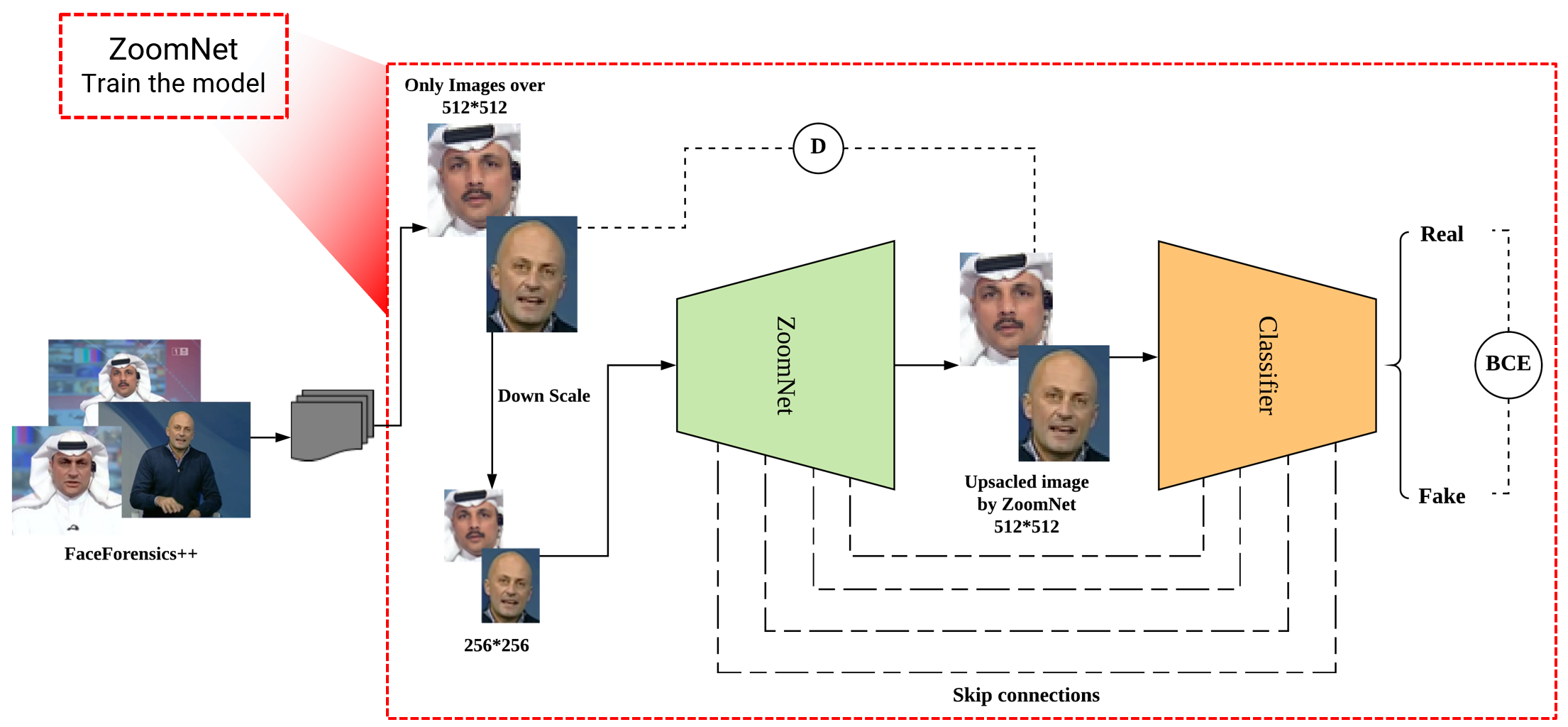
As the number of lonely deaths increases due to the aging population and the increase in single-person households, the frequency of discovery of decomposed corpses in death cases is gradually increasing. In the wake of the strengthening of on-site guidelines by the National Police Agency and the adjustment of the prosecution and police investigation rights, the need for identification and autopsy at the scene is being emphasized. Although the existing forensic face restoration technology using face bones has accumulated a number of previous studies, there is a limitation in that the restoration results may vary due to many factors such as the thickness and nature of facial soft tissue, shape of eyes or nose, and distribution of body hair. Based on the fact that facial recognition technology using facial landmarks is becoming common all over the world, this study aims to help quickly and accurately identify the faces of corrupt bodies that expand due to postmortem-change.
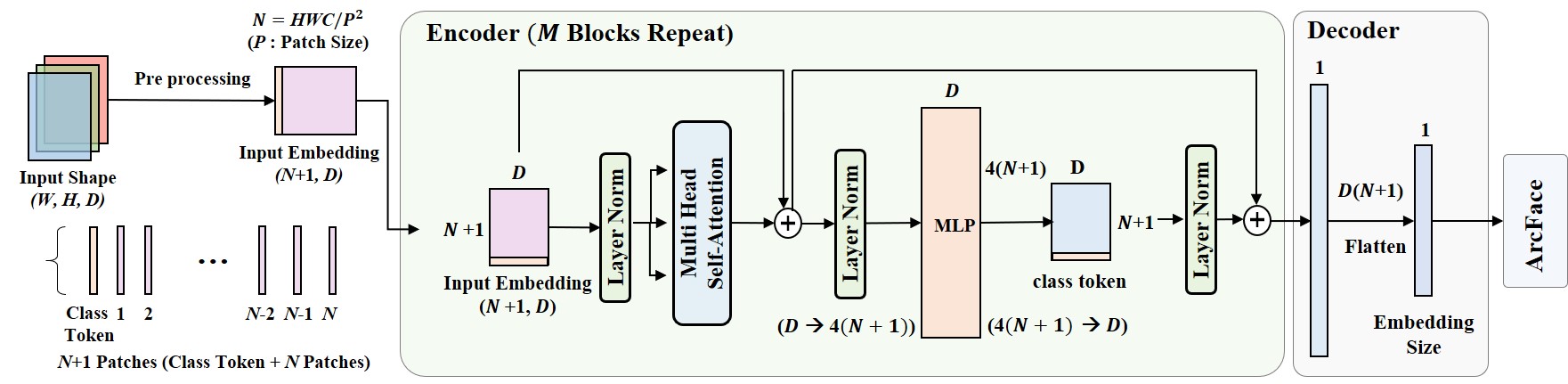
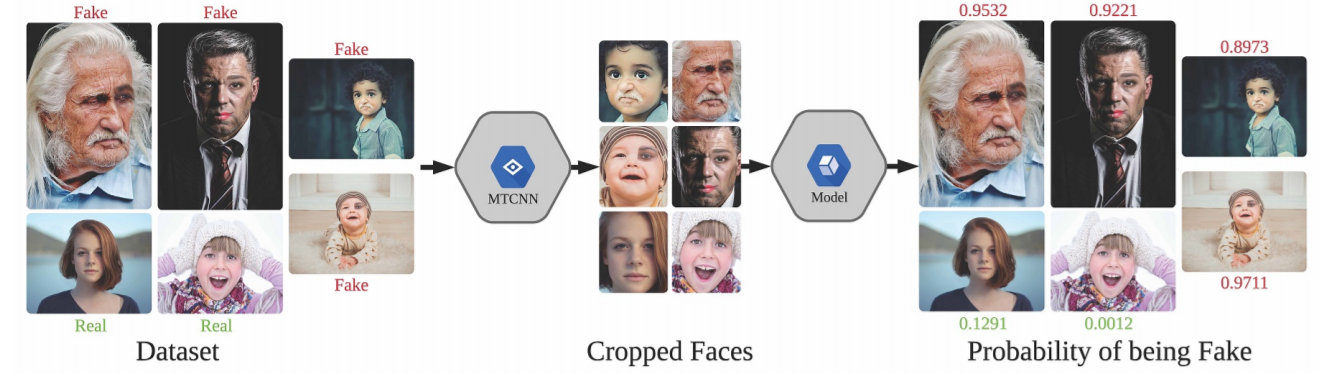
In this study, living data such as ID cards and post-mortem data were collected for bodies identified with fingerprints, and compared pairs were formed, and face recognition technology used the MTCNN model, which is currently widely used in the field. The artificial intelligence model, which determines whether live data and post-data match, selected and analyzed Arcface, which is the same among a total of seven open-source models (VGG-Face, FaceNet, OpenFace, DeepFace, DeepID, ArcFace, Dlib).
The performance of the artificial intelligence model (Arcface) was evaluated by comparing the results of the judgment of the expert group, the general public group, and the entire human group. As a result of comparison using 107 pairs of original data, the same person judgment rate was found to be 51.4% in the expert group, 22.4% in the general population, and 29.0% in the total human group, and the artificial intelligence model was 47.7%. As a result of reviewing the original data, it was determined that changes in skin color due to decomposition could affect the performance of artificial intelligence models According to this judgment, when the original data were preprocessed in gray scale, the judgment rate of the same person as the artificial intelligence model was 50.5%, which showed an improvement in performance of about 3%.
Through this study, it was found that only the currently developed artificial intelligence model showed facial recognition performance close to that of a group of experts. It is expected that face recognition performance can be further improved if various pretreatment technologies reflecting the characteristics of the postmortem change are developed and applied in the future.
인구 고령화 및 1인 가구의 증가는 고독사의 증가로 이어져 변사사건에서 부패 시신이 발견되는 빈도가 점차 높아지고 있다. 경찰청의 현장 지침 강화 및 검경 수사권 조정 등을 계기로 현장에서는 신원 확인 및 부검의 필요성이 강조되고 있다. 얼굴뼈를 활용한 기존의 법의학적 얼굴 복원 기술은 다수의 선행연구 결과가 축적되어 있지만, 얼굴 연부조직의 두께나 성상, 눈이나 코의 형태, 체모의 분포 등의 고려 요소가 많아 복원 결과가 달라질 수 있다는 한계가 존재한다. 본 연구는 얼굴의 특징점(face landmark)을 활용하는 얼굴 인식 기술이 전세계적으로 보편화되고 있다는 점에 착안하여, 사후변화로 인해 연부조직이 팽창된 부패 시신의 얼굴을 복원하거나 생전의 사진과 비교하여 동일인 여부를 판정함으로써 신속하고 정확한 신원확인에 도움을 주고자 한다.
본 연구에서는 지문 등으로 신원이 확인된 시신을 대상으로 신분증 등의 생전 데이터와 검안 또는 부검 당시 촬영된 사후데이터를 수집한 뒤 각각 짝을 지어 비교쌍을 구성하였으며, 얼굴 인식 기술은 현재 해당 분야에서 많이 활용되고 있는 MTCNN 모델을 활용하였다. 생전데이터와 사후데이터의 일치 여부를 판단하는 인공지능모델은 총 7개의 open source 모델(VGG-Face, FaceNet, OpenFace, DeepFace, DeepID, ArcFace, Dlib) 중 가장 동일인 판정률의 빈도가 가장 높게 나타난 Arcface를 선정하여 분석하였다.
인공지능모델(Arcface)의 성능은 전문가집단과 일반인 집단, 전체 사람 집단의 판정 결과와 비교하여 평가하였다. 원본 데이터 107쌍을 이용한 비교 결과, 동일인 판정률은 전문가집단 51.4%, 일반인 22.4%, 전체 사람 집단 29.0%로 조사되었으며, 인공지능모델은 47.7%로 나타났다. 원본 데이터를 검토한 결과, 부패로 인한 피부색의 변화가 인공지능모델의 성능에 영향을 줄 가능성이 있다고 판단되었다. 이러한 판단에 따라 원본 데이터를 회색조(gray scale)로 전처리하였을 때 인공지능모델의 동일인 판정률은 50.5%로, 약 3%의 성능이 향상되는 것을 볼 수 있었다.
본 연구를 통해 현재 개발되어 있는 인공지능모델만으로도 전문가 집단에 근접한 얼굴 인식 성능을 보이는 것을 알 수 있었다. 향후 사후변화의 특성을 반영한 다양한 전처리 기법을 개발하여 적용할 경우 얼굴 인식 성능을 더욱 향상시킬 수 있을 것으로 기대된다.