Publications
2025
Binh M. Le, Jiwon Kim, Simon S. Woo* , Shahroz Tariq, Alsharif Abuadbba, and Kristen Moore
10th IEEE European Symposium on Security and Privacy (Euro S&P), Venice, July, 2025 (Acceptance rate = 8%)
This paper extensively reviews and analyzes state-of-the-art deepfake detectors, evaluating them against several critical criteria. These criteria categorize detectors into 4 high-level groups and 13 fine-grained sub-groups, aligned with a unified conceptual framework we propose. This classification offers practical insights into the factors affecting detector efficacy. We evaluate the generalizability of 16 leading detectors across comprehensive attack scenarios, including black-box, white-box, and gray-box settings. Our systematized analysis and experiments provide a deeper understanding of deepfake detectors and their generalizability, paving the way for future research and the development of more proactive defenses against deepfakes.
Muhammad Shahid Muneer and Simon S. Woo*
International World Wide Web Conference (WWW) 2025 Sydney, Australia
BK Computer Science 최우수학회 IF=3 (Short Paper)
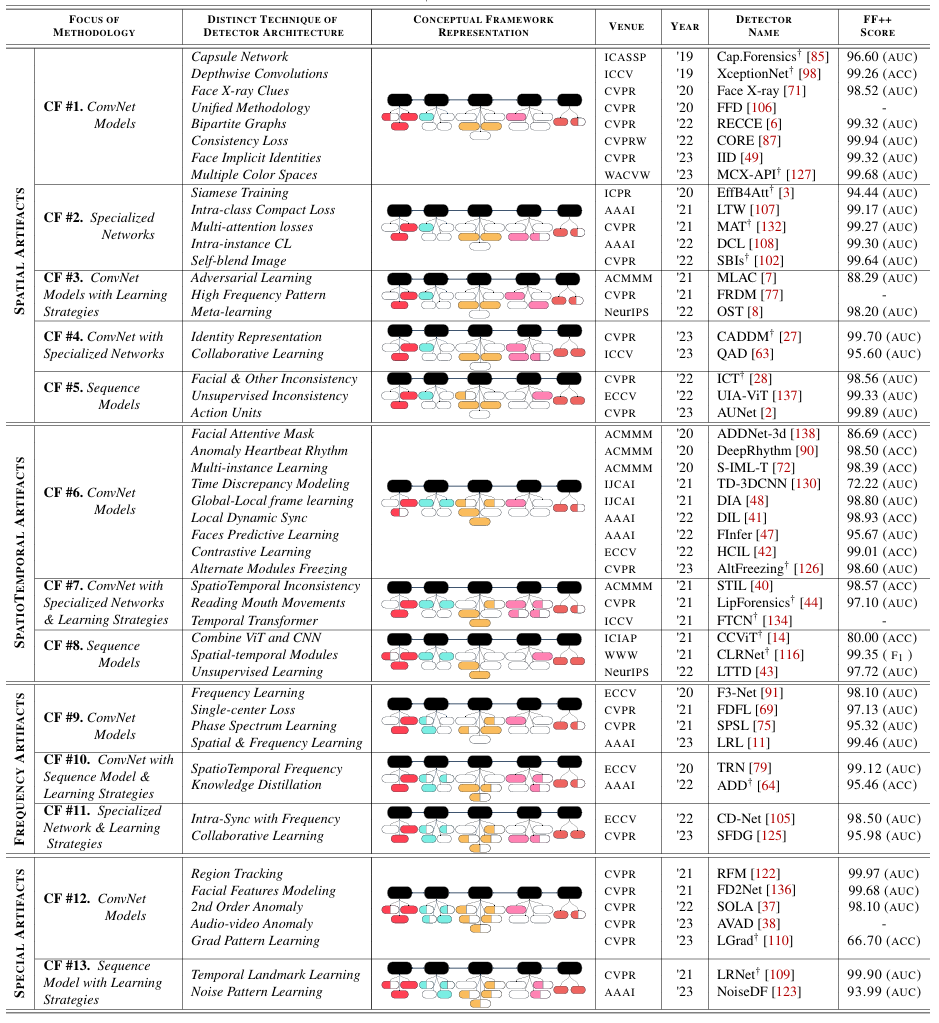
Defensive mechanisms such as NSFW and post-hoc security filters are implemented in T2I models to mitigate the misuse of T2I models and develop a safe online ecosystem for web users. However, recent work unveiled how these methods can easily fail to prevent misuse. In particular, careful adversarial attacks on text and image modalities can easily outplay defensive measures. Moreover, there is no robust millionscale multimodal NSFW dataset with both prompt and image pairs with adversarial examples. In this work, we propose a large-scale prompt and image dataset, generated using open-source diffusion models. Also, we develop a multimodal classification model to distinguish safe and NSFW text and images, which has robustness against adversarial attacks, and directly alleviates the current challenges. Our extensive experimental results show that our model shows good performance against existing SOTA NSFW detection methods in terms of accuracy and recall, and drastically reduced the Attack Success Rate (ASR) in multimodal adversarial attack scenarios.
Khoa Tran and Simon S. Woo*
International World Wide Web Conference (WWW) 2025 Sydney, Australia
BK Computer Science 최우수학회 IF=3 (Short Paper)
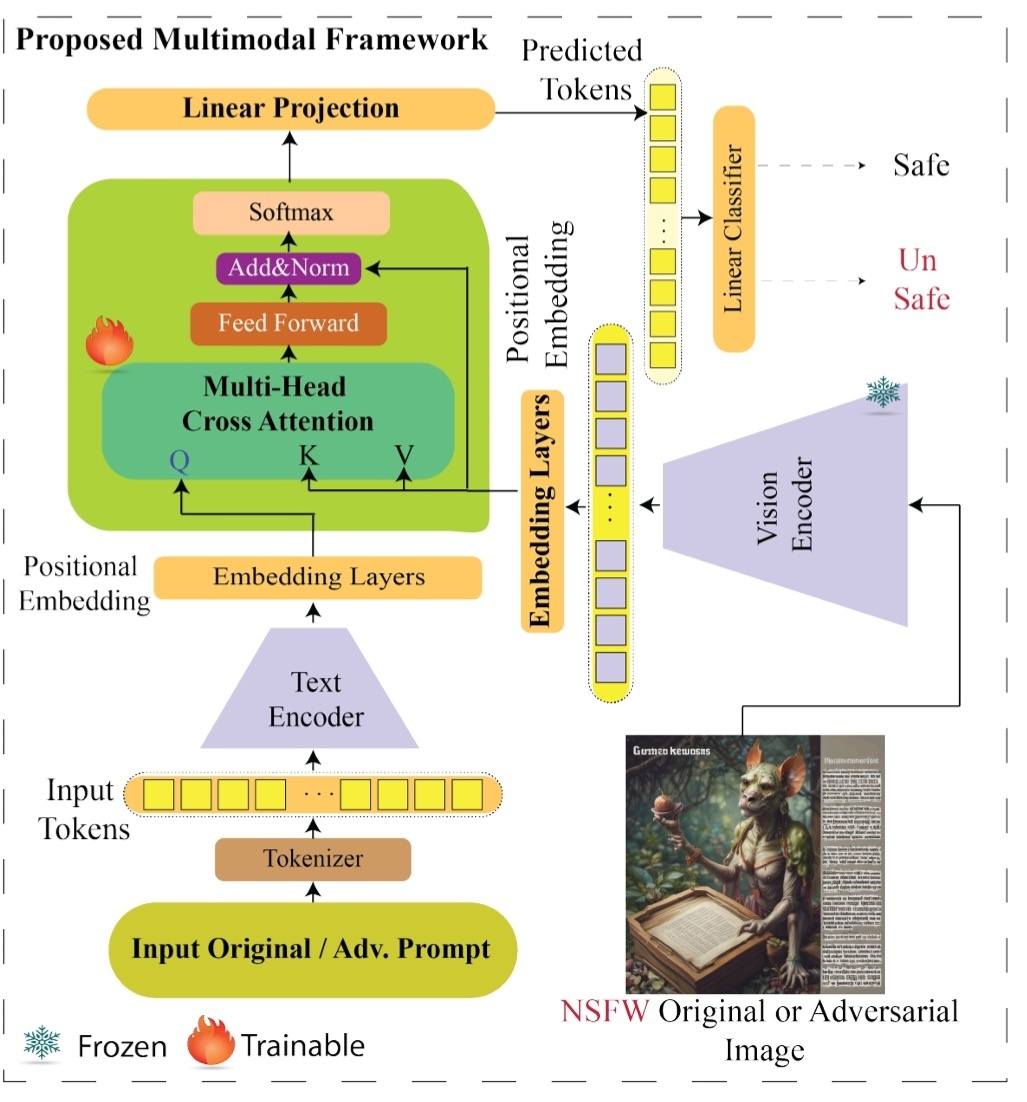
Our study presents fairness Conjectures for a well-trained model, based on the variance-bias trade-off characteristic, and considers their relevance to robustness. Our Conjectures are supported by experiments conducted on the two most widely used model architectures—ResNet and ViT—demonstrating the correlation between fairness and robustness: the higher fairness-gap is, the more the model is sensitive and vulnerable. In addition, our experiments demonstrate the vulnerability of current state-of-the-art approximated unlearning algorithms to adversarial attacks, where their unlearned models suffer a significant drop in accuracy compared to the exact-unlearned models.We claim that our fairness-gap measurement and robustness metric should be used to evaluate the unlearning algorithm. Furthermore, we demonstrate that unlearning in the intermediate and last layers is sufficient and cost-effective for time and memory complexity.
Inzamamul Alam, Md Tanvir Islam and Simon S. Woo*
International World Wide Web Conference (WWW) 2025 Sydney, Australia
BK Computer Science 최우수학회 IF=3 (Short Paper)
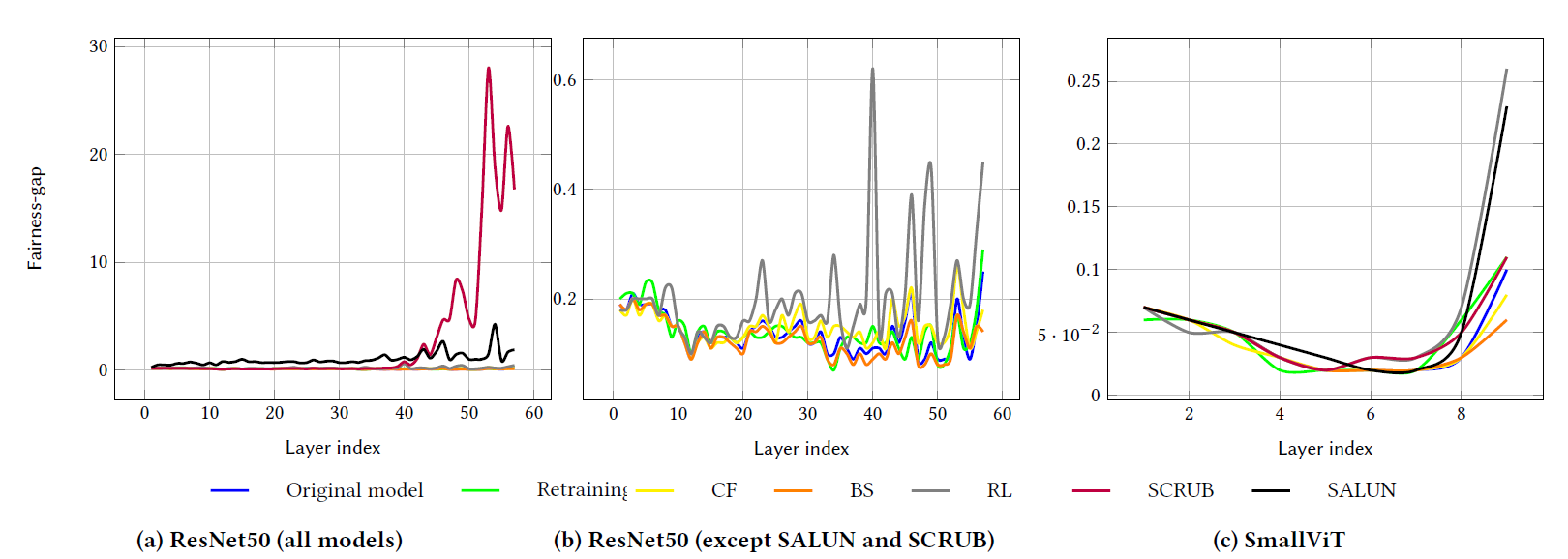
This paper introduces a novel Saliency-Aware Diffusion Reconstruction (SADRE) framework for watermark elimination on the web, combining adaptive noise injection, region-specific perturbations, and advanced diffusion-based reconstruction. SADRE disrupts embedded watermarks by injecting targeted noise into latent representations guided by saliency masks although preserving essential image features. A reverse diffusion process ensures high-fidelity image restoration, leveraging adaptive noise levels determined by watermark strength. Our framework is theoretically grounded with stability guarantees and achieves robust watermark removal across diverse scenarios. Empirical evaluations on state-of-the-art (SOTA) watermarking techniques demonstrate SADRE’s superiority in balancing watermark disruption and image quality, achieving the best performance in PSNR, SSIM, Wasserstein Distance, and Bit Recovery Accuracy. By bridging the gap between theoretical robustness and practical effectiveness, SADRE sets a new benchmark for watermark elimination, offering a flexible and reliable solution for real-world web contents.
Youngho Jun, Minha Kim, Kangjun Lee and Simon S. Woo*
World Electric Vehicle Journal (WEVJ)
(Accepted) ESCI Q2 IF = 2.6
The smart regenerative braking system for EV can reduce unnecessary brake operation by assisting in braking of the vehicle according to the driving situation, road slope, and driver’s preference. This system maintains the distance between the ego and front vehicles without controlling the brake pedal. Since the strength of regenerative braking is generally determined based on calibration data determined during the vehicle development process, some driver could suffer inconvenience when the regenerative braking is activated differently from their driving habits. In order to solve this problem, various deep learning-based algorithms are developed to provide driving stability by learning the driving data. Among those artificial intelligence algorithms, anomaly detection algorithms can successfully separate the deceleration data in abnormal driving situations, and the resulting refined deceleration data can be used to train the regression model to achieve better driving stability. This study evaluates the performance of a personalized driving assistance system by applying driver characteristic data, obtained through an anomaly detection algorithm, to vehicle control.
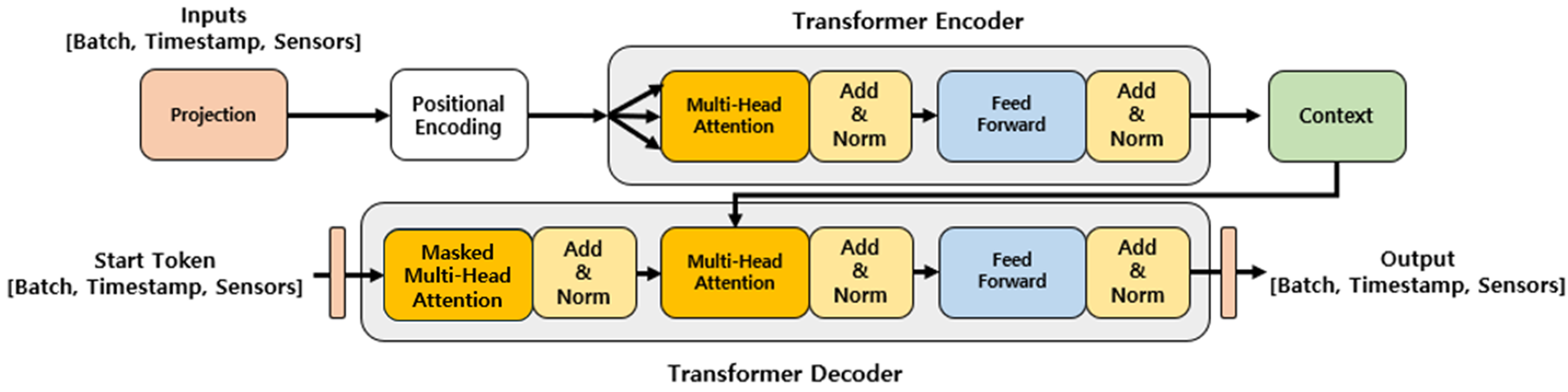
Hyeongjun Choi and Simon S. Woo*
The 40th ACM/SIGAPP Symposium on Applied Computing (SAC), Sicily, Italy, April, 2025
BK Computer Science IF = 1
In this work, we train popular deep neural networks using face data generated by various generative models and thoroughly analyze their generalizability. Our results reveal significant differences in model performance based on the forgery method used to generate the training data. Notably, we identify specific scenarios that significantly enhance model generalization, contradicting previous research finding that models trained on DM-generated data would achieve higher generalization performance than those trained on GAN-generated data. These findings emphasize the crucial role of training data selection in enhancing the generalization capabilities of deepfake detectors. By strategically selecting and combining datasets, we can develop more robust detection systems, laying a foundation for future research in creating reliable and universal deepfake detection methods

Chan Park, Bohyun Moon, Minsun Jeon, Jee-Weon Jung and Simon S. Woo*
The 40th ACM/SIGAPP Symposium on Applied Computing (SAC), Sicily, Italy, April, 2025
BK Computer Science IF = 1
In this work, we propose X3A, an efficient multimodal video deepfake detection model exploiting two powerful unimodal models with probabilistic score-level fusion. X3A leverages the advantage of using raw visual and audio inputs without relying on hand-crafted features. We conducted the extensive experiments on multiple different multimodal deepfake benchmark datasets and achieved superior performance on multimodal deepfake detection, successively detecting entirely and partially manipulated scenarios. Our X3A model demonstrates an accuracy of 0.9960 AUC of 0.9999 on the most challenging AVDeepfake1M benchmark, surpassing all existing models.

Hakjun Moon, Dayeon Woo and Simon S. Woo*
The 40th ACM/SIGAPP Symposium on Applied Computing (SAC), Sicily, Italy, April, 2025
BK Computer Science IF = 1
We introduce a novel GAN-based face age transformation framework utilizing Hierarchical Encoding and Contrastive Learning (HECL). Specifically, we incorporate a multi-level encoder that extracts and analyzes age-related features at different levels of detail, such as facial texture, structure, and skin tone. We also combined a contrastive learning approach in the discriminator to finetune the differentiation between age groups. These modifications enhance identity preservation and provide better control over aging through strategic loss functions, addressing shortcomings in existing models, which often struggle with modifying subtle face and hair texture, color, or volume during age progression. HECL outperforms SOTA models in realism and versatility, generating high-quality face images. We demonstrate superior identity preservation performance in metrics, also receiving better qualitative approval from human evaluators.

Inzamamul Alam, Md. Samiullah*, S M Asaduzzaman, Upama Kabir, A.M. Aahad and Simon S. Woo*
Data Mining and Knowledge Discovery
(Accepted) SCIE Q1 IF = 5.3 (5-year Journal Impact Factor)
We propose a novel approach, Malware Image Recognition & Classification by Layered Extraction (MIRACLE), by implementing our own spatial convolutional neural network (Sp-CNN) with sufficient regularization and data augmentation to identify and classify malware in images effectively and efficiently. Our proposed method is developed based on analyzing malware binary structure, which is segmented as headers and section, symbolic information lies on section segment. Our Sp-CNN can extract that symbolic information from the top of the hidden layer constructively. We have evaluated our model with as MalImg, Microfsoft-Big, Malevis and Android Malware dataset. We achieved accuracy of 99.87% for MalImg, 99.81% for Microsoft-Big, and 99.22% for Malevis in our test dataset, respectively. Our proposed method surpasses Google's InceptionV3, ResNet50, EfficientNetB1, VGG16, VGG19, and other state-of-the-art (SOTA) methods in terms of performance.

2024
Minsun Jeon and Simon S. Woo*
Conference on Information Security and Cryptography 2024 Winter (CISC-W), Gyeonggi-do, Korea, November 2024
With the growing need to simultaneously address privacy protection and data utilization, synthetic data, a powerful anonymization technique, is gaining attention. This paper examines the types of synthetic data, key generation methods for different target subjects, and various application cases. Through this exploration, we aim to provide a more detailed understanding of synthetic data's advantages and potential applications, as well as insights into future research directions for expanding its use.
Minsun Jeon and Simon S. Woo*
Conference on Korean Artificial Intelligence Association (KAIA), Seoul, Korea, November 2024
Deepfake content is being created automatically in large quantities, but it must still be reported manually by victims, making rapid responses difficult. Despite the prevalence of sexually exploitative deepfake, no existing approach has combined Not Safe For Work (NSFW) detection with deepfake detection. To address this issue, this study proposes a novel integrated process that first implements NSFW detection to assess urgency and identify sexual components before proceeding to deepfake detection. To verify the effectiveness of this process, we generated eight FaceSwap images. In addition, we utilized these images to evaluate the performance of the NSFW and deepfake detection models, achieving an accuracy of 87.5% and 100%, respectively. The results demonstrated the viability of a sequential detection approach. This research highlights the importance of combining NSFW and deepfake detection for more efficient and urgent content moderation, providing a practical tool for law enforcement and victim support organizations. In our findings, this research presents a paradigm that enables rapid responses to address the harms caused by deepfake content effectively and promotes a more proactive approach to content moderation.

Yujeong Kwon, Simon S. Woo* , and Hyungjoon Koo
International Symposium on Foundations and Practice of Security (FPS 2024) Montreal, Canada, December, 2024
The recent advancements in artificial intelligence drive the widespread adoption of Machine-Learning-as-a-Service platforms, which offer valuable services. However, these pervasive utilities in the cloud environment unavoidably encounter security and privacy issues. In particular, a membership inference attack (MIA) poses a threat by recognizing the presence of a data sample in a training set for the target model. Although prior MIA approaches underline privacy risks repeatedly by demonstrating experimental results with standard benchmark datasets such as MNIST and CIFAR, the effectiveness of such techniques on a real-world dataset remains questionable. We are the first to perform an in-depth empirical study on black-box-based MIAs that hold realistic assumptions, including six metric-based and three classifier-based MIAs with the high-dimensional image dataset that consists of identification (ID) cards and driving licenses. Additionally, we introduce the Siamese-based MIA that shows similar or better performance than the state-of-the-art approaches and suggest training a shadow model with autoencoder-based reconstructed images. Our major findings show that the performance of MIA techniques against too many features may be degraded; the MIA configuration or a sample's properties can impact the accuracy of membership inference on members and non-members.

Md Islam, Inzamamul Alam, Simon S. Woo*, Saeed Anwar, Ik Hun Lee, and Khan Muhammad*
The 17th International Asian Conference on Computer Vision (ACCV 2024) Hanoi, Vietnam, December 2024
BK Computer Science IF = 1
We introduce a new large-scale dataset “LoLI-Street” (Low-Light Images of Streets) with 33k paired low-light and well-exposed images from street scenes in developed cities, covering 19k object classes for object detection, including Person, Bicycle, Car, Bus, Motorcycle, and Traffic Light, etc. LoLI-Street dataset also features 1,000 real low-light test images, providing a benchmark for evaluating models under real-world conditions. Furthermore, we propose a transformer and diffusion-based LLIE model named “TriFuse”. Leveraging the LoLI-Street dataset, we train and evaluate our TriFuse and other SOTA models to benchmark our dataset. Comparing various models, the feasibility of our dataset for generalization is evident in testing across different mainstream datasets by significantly enhancing low-quality images and object detection for practical applications in autonomous driving and surveillance systems. The benchmark dataset and the evaluation code will be released to ensure reproducibility.

Binh M. Le, Shahroz Tariq, and Simon S. Woo
The 17th International Asian Conference on Computer Vision (ACCV 2024) Hanoi, Vietnam, December 2024
BK Computer Science IF = 1 (Oral Talk, 5.6%)
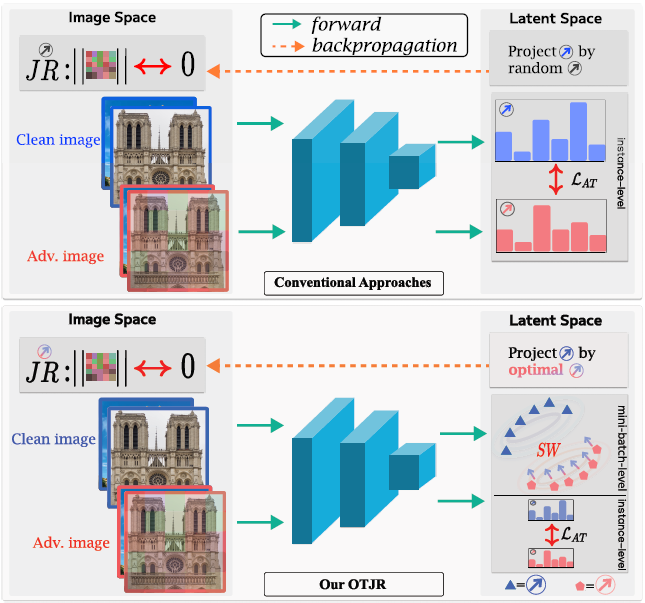
Deep neural networks, particularly in vision tasks, are notably susceptible to adversarial perturbations. To overcome this chal lenge, developing a robust classifier is crucial. In light of the recent advancements in the robustness of classifiers, we delve deep into the intricacies of adversarial training and Jacobian regularization, two pivotal defenses. Our work is the first carefully analyzes and characterizes these two schools of approaches, both theoretically and empirically, to demonstrate how each approach impacts the robust learning of a classifier. Next, we propose our novel Optimal Transport with Jacobian regularization method, dubbed OTJR, bridging the input Jacobian regularization with the a output representation alignment by leveraging the optimal transport theory. In particular, we employ the Sliced Wasserstein distance that can efficiently push the adversarial samples’ representations closer to those of clean samples, regardless of the number of classes within the dataset. The SW distance provides the adversarial samples’ movement directions, which are much more informative and powerful for the Jacobian regularization. Our empirical evaluations set a new standard in the domain, with our method achieving commendable accuracies of 52.57% on CIFAR-10 and 28.36% on CIFAR-100 datasets under the AutoAttack. Further validating our model’s practicality, we conducted real-world tests by subjecting internet-sourced images to online adversarial attacks. These demonstrations highlight our model’s capability to counteract sophisticated adversarial perturbations, affirming its significance and applicability in real-world scenarios.

Zeliang Xu, Dong In Kim, and Simon S. Woo
The 15th International Conference on Information and Communication Technology Convergence (ICTC 2024) Jeju Island, Korea, October, 2024
This paper proposes a novel cloud-edge collaborative distributed diffusion model for AI-generated content (AIGC) such as image generation, which integrates adaptive clustering techniques with dynamic step-size optimization. The proposed model addresses the challenges of heterogeneous edge devices in real-world deployments. Experimental results demonstrate significant improvements in performance and efficiency with a 38.8% reduction in average generation time and a 15.6% increase in image quality (evaluate via CLIP score). The system shows enhanced resource utilization, improving cloud and edge utilization by 16.1% and 36.6%, respectively. This research contributes to the advancement of collaborative distributed diffusion model, offering a scalable and adaptive framework for efficient AIGC services in dynamic environments along with potential applications extending to other computationally intensive tasks in cloud-edge systems.

Juhong Jung, Ju Hwan Kim, Ji-Hwan Bae, Simon S. Woo* , Hyesung Lee, and Ju-Young Shin
Scientific Reports, June 2024
SCIE
In this study, gradient boosting machine algorithm-based model was fitted to identify safety signals of serious cardiovascular AEs reported for tisagenlecleucel in the World Health Organization Vigibase up until February 2024. Input dataset, comprised of positive and negative controls of tisagenlecleucel based on its labeling information and literature search, was used to train the model. Then, we implemented the model to calculate the predicted probability of serious cardiovascular AEs defined by preferred terms included in the important medical event list from European Medicine Agency. There were 467 distinct AEs from 3,280 safety cases reports for tisagenlecleucel, of which 363 (77.7%) were classified as positive controls, 66 (14.2%) as negative controls, and 37 (7.9%) as unknown AEs. The prediction model had area under the receiver operating characteristic curve of 0.76 in the test dataset application. Of the unknown AEs, six cardiovascular AEs were predicted as the safety signals: bradycardia (predicted probability 0.99), pleural effusion (0.98), pulseless electrical activity (0.89), cardiotoxicity (0.83), cardio-respiratory arrest (0.69), and acute myocardial infarction (0.58). Our findings underscore vigilant monitoring of acute cardiotoxicities with tisagenlecleucel therapy.

Kangjun Lee, and Simon S. Woo*
27th International Conference on Pattern Recognition (ICPR), Kolkata, India, December 2024
BK Computer Science IF = 1
Satellite orbit propagation (SOP) are of prime importance in the prevention of collision and completion of the assigned task of the satellites. In the past, orbit prediction and propagation have relied on physics-based mathematical model. However, as the number of satellites and their data increases, it is crucial to explore the data-driven orbit propagation based on the advanced machine learning methods. In this work, we propose a novel deep learning-based framework to forecast future satellite orbit states. The proposed framework employs a model based on Neural Controlled Differential Equations (NCDEs) to train orbit prediction models, and our approach captures features from past satellite state values at both fixed and dynamic time intervals. The experimental results on Korea Aerospace Research Institute (KARI)’s KOMPSAT-3 and 5 datasets demonstrate that the proposed framework outperforms the other eight data-driven baseline forecasting models.

Kishor Kumar Bhaumik, Minha Kim, Fahim Faisal Niloy, Amin Ahsan Ali, and Simon S. Woo*
27th International Conference on Pattern Recognition (ICPR), Kolkata, India, December 2024
BK Computer Science IF = 1
Traffic forecasting in Intelligent Transportation Systems (ITS) is vital for intelligent traffic prediction. Yet, ITS often relies on data from traffic sensors or vehicle devices, where certain cities might not have all those smart devices or enabling infrastructures. Also, recent studies have employed meta-learning to generalize spatial-temporal traffic networks, utilizing data from multiple cities for effective traffic forecasting for data-scarce target cities. However, collecting data from multiple cities can be costly and time-consuming. To tackle this challenge, we introduce Single Source Meta-Transfer Learning (SSMT ) which relies only on a single source city for traffic prediction. Our method harnesses this transferred knowledge to enable few-shot traffic forecasting, particularly when the target city possesses limited data. Specifically, we use memory-augmented attention to store the heterogeneous spatial knowledge from the source city and selectively recall them for the data-scarce target city. We extend the idea of sinusoidal positional encoding to establish meta-learning tasks by leveraging diverse temporal traffic patterns from the source city. Moreover, to capture a more generalized representation of the positions we introduced a meta-positional encoding that learns the most optimal representation of the temporal pattern across all the tasks. We experiment on five real-world benchmark datasets to demonstrate that our method outperforms several existing methods in time series traffic prediction.

Minha Kim, Kishor Kumar Bhaumik, Amin Ahsan Ali, and Simon S. Woo*
27th International Conference on Pattern Recognition (ICPR), Kolkata, India, December 2024
BK Computer Science IF = 1 (Oral)
For modern industrial applications, accurately detecting and diagnosing anomalies in multivariate time series data is essential. Despite this need, most state-of-the-art methods often prioritize detection performance over model interpretability. Addressing this gap, we introduce MIXAD (Memory-Induced Explainable Time Series Anomaly Detection), a model designed for interpretable anomaly detection. MIXAD leverages a memory network alongside spatiotemporal processing units to understand the intricate dynamics and topological structures inherent in sensor relationships. We also introduce a novel anomaly scoring method that detects significant shifts in memory activation patterns during anomalies. Our approach not only ensures decent detection performance but also outperforms state-of-the-art baselines by 34.30% and 34.51% in interpretability metrics.

Inzamamul Alam, Muhammad Shahid Muneer, and Simon S. Woo*
BK Computer Science IF = 3 (full paper)
In the wake of a fabricated explosion image at the Pentagon, an ability to discern real images from fake counterparts has never been more critical. Our study introduces a novel multi-modal approach to detect AI-generated images amidst the proliferation of new generation methods such as Diffusion models. Our method, UGAD, encompasses three key detection steps: First, we transform the RGB images into YCbCr channels and apply an Integral Radial Operation to emphasize salient radial features. Secondly, the Spatial Fourier Extraction operation is used for a spatial shift, utilizing a pre-trained deep learning network for optimal feature extraction. Finally, the deep neural network classification stage processes the data through dense layers using softmax for classification. Our approach significantly enhances the accuracy of differentiating between real and AI-generated images, as evidenced by a 12.64% increase in accuracy and 28.43% increase in AUC compared to ex- isting state-of-the-art methods. Also, we integrated and deployed 1 our approach to detect real-world deepfakes in our system.

Hyumin Choi, Jiwon Kim, Chiyoung Song, Simon S. Woo*, and Hyoungshick Kim*
BK Computer Science IF = 3 (full paper)
We present Blind-Match, a novel biometric identification system that leverages homomorphic encryption (HE) for efficient and privacy- preserving 1:N matching. Blind-Match introduces a HE-optimized cosine similarity computation method, where the key idea is to divide the feature vector into smaller parts for processing rather than comput- ing the entire vector at once. By optimizing the number of these parts, Blind-Match minimizes execution time while ensuring data privacy through HE. Blind-Match achieves superior performance compared to state-of-the-art methods across various biometric datasets. On the LFW face dataset, Blind-Match attains a 99.63% Rank-1 ac- curacy with a 128-dimensional feature vector, demonstrating its robustness in face recognition tasks. For fingerprint identification, Blind-Match achieves a remarkable 99.55% Rank-1 accuracy on the PolyU dataset, even with a compact 16-dimensional feature vector, significantly outperforming the state-of-the-art method, Blind-Touch, which achieves only 59.17%. Furthermore, Blind-Match showcases practical efficiency in large-scale biometric identification scenarios, such as Naver Cloud’s FaceSign, by processing 6,144 biometric samples in 0.74 seconds using a 128-dimensional feature vector.

Girim Ban, Hyeonseok Yun, Banseok Lee, David Sung, and Simon S. Woo*
BK Computer Science IF = 3 (full paper)
In digital marketing, precise audience targeting is crucial for campaign efficiency. However, digital marketing agencies often struggle with incomplete user profiles and interaction details from Advertising Identifier (ADID) data in user behavior modeling. To address this, Korea Telecom (KT), a leading telecommunication and big data service provider in South Korea, introduces the Deep Journey Hierarchical Attention Networks (DJHAN). This novel method enhances conversion predictions by leveraging heterogeneous action sequences associated with ADIDs and encapsulating these interactions into structured journeys. These journeys are hierarchically aggregated to effectively represent ADID’s behavioral attributes. Moreover, DJHAN incorporates three specialized attention mechanisms: temporal attention for time-sensitive contexts, action attention for emphasizing key behaviors, and journey attention for highlighting influential journeys in the purchase conversion process. Emprically, DJHAN surpasses state-of-the-art (SOTA) models across three diverse datasets, including real-world data from NasMedia, a leading media representative in Asia. In backtesting simulations with three advertisers, DJHAN outperforms existing baselines, achieving the highest improvements in Conversion Rate (CVR) and Return on Ad Spend (ROAS) across three advertisers, demonstrating its practical potential in digital marketing.

Seungyeon Back, Geonho Son, Dahye Jeong, Eunil Park, and Simon S. Woo*
Photo restoration technology enables preserving visual memories in photographs. However, physical prints are vulnerable to various forms of deterioration, ranging from physical damage to loss of image quality, etc. While restoration by human experts can improve the quality of outcomes, it often comes at a high price in terms of cost and time for restoration. In this work, we present the AI- based photo restoration framework composed of multiple stages, where each stage tailored to enhance and restore specific types of photo damage, accelerating and automating the photo restoration process. By integrating these techniques into a unified architecture, our framework aims to offer a one-stop solution for restoring old and deteriorated photographs. Furthermore, we present a novel old photo restoration dataset due to the lack of publicly available dataset for our evaulation.

Joo Chan Lee, Taejune Kim, Eunbyung Park, Simon S. Woo* , and Jong Hwan Ko
The 18th European Conference on Computer Vision (ECCV 2024), Milan, September 2024
BK Computer Science IF = 2
There have been significant advancements in anomaly detection in an unsupervised manner, where only normal images are available for training. Several recent methods aim to detect anomalies based on a memory, comparing or reconstructing the input with directly stored normal features (or trained features with normal images). However, such memory-based approaches operate on a discrete feature space implemented by the nearest neighbor or attention mechanism, suffering from poor generalization or an identity shortcut issue outputting the same as input, respectively. Furthermore, the majority of existing methods are designed to detect single-class anomalies, resulting in unsatisfactory performance when presented with multiple classes of objects. To tackle all of the above challenges, we propose CRAD, a novel anomaly detection method for representing normal features within a “continuous” memory,enabled by transforming spatial features into coordinates and mapping them to continuous grids. Furthermore, we carefully design the grids tailored for anomaly detection, representing both local and global normal features and fusing them effectively. Our extensive experiments demonstrate that CRAD successfully generalizes the normal features and mitigates the identity shortcut, furthermore, CRAD effectively handles diverse classes in a single model thanks to the high-granularity continuous representation. In an evaluation using the MVTec AD dataset, CRAD significantly outperforms the previous state-of-the-art method by reducing 65.0% of the error for multi-class unified anomaly detection.

Taejune Kim, Yun-Gyoo Lee, Inho Jung, Soo-Youn Ham, and Simon S. Woo*
Pattern Recognition Letters
SCIE Q1 IF = 5.1 (Accepted on June 2024)
Radiography images inherently possess globally consistent structures while exhibiting significant diversity in local anatomical regions, making it challenging to model their normal features through unsupervised anomaly detection. Since unsupervised anomaly detection methods localize anomalies by utilizing discrepancies between learned normal features and input abnormal features, previous studies introduce a memory structure to capture the normal features of radiography images. However, these approaches store extremely localized image segments in their memory, causing the model to represent both normal and pathological features with the stored components. This poses a significant challenge in unsupervised anomaly detection by reducing the disparity between learned features and abnormal features. Furthermore, with the diverse settings in radiography imaging, the above issue is exacerbated: more diversity in the normal images results in stronger representation of pathological features. To resolve the issues above, we propose a novel pathology detection method called Patch-wise Vector Quantization (P-VQ). Unlike the previous methods, P-VQ learns vector-quantized representations of normal "patches" while preserving its spatial information by incorporating vector similarity metric. Furthermore, we introduce a novel method for selecting features in the memory to further enhance the robustness against diverse imaging settings. P-VQ even mitigates the "index collapse" problem of vector quantization by proposing top-k% dropout. Our extensive experiments on the BMAD benchmark demonstrate the superior performance of P-VQ against existing state-of-the-art methods.

Razaib Tariq, Simon S. Woo* and Shahroz Tariq
Deepfake detection is critical in mitigating the societal threats posed by manipulated videos. While various algorithms have been developed for this purpose, challenges arise when detectors operate externally, such as on smartphones, when users take a photo of deepfake images and upload on the Internet. One significant challenge in such scenarios is the presence of Moiré patterns, which degrade image quality and confound conventional classification algorithms, including deep neural networks (DNNs). The impact of Moiré patterns remains largely unexplored for deepfake detectors. In this study, we investigate how camera-captured deepfake videos from digital screens affect detector performance. We conducted experiments using two prominent datasets, CelebDF and FF++, comparing the performance of four state-of-the-art detectors on camera-captured deepfake videos with introduced Moiré patterns. Our findings reveal a significant decline in detector accuracy, with none achieving above 68% on average. This underscores the critical need to address Moiré pattern challenges in real-world deepfake detection scenarios.

SeungWon Jeong, Soyeon Woo, Daewon Chung, Simon S. Woo , and Youjin Shin
International Conference on Knowledge Discovery and Data Mining (SIGKDD), Barcelona, Spain, 2024
BK Computer Science IF=4
As the focus of space exploration shifts from national agencies to private companies, the interest in space industry has been steadily increasing. With the increasing number of satellites, the risk of collisions between satellites and space debris has escalated, potentially leading to significant property and human losses. Therefore, accurately modeling the orbit is critical for satellite operations. In this work, we propose the Decomposed Attention Segment Recurrent Neural Network (DASR) model, adding two key components, Multi-Head Attention and Tensor Train Decomposition, to SegRNN for orbit prediction. The DASR model applies Multi-Head Attention before segmenting at input data and before the input of the GRU layers. In addition, Tensor Train (TT) Decomposition is applied to the weight matrices of the Multi-Head Attention in both the encoder and decoder. For evaluation, we use three real-world satellite datasets from the Korea Aerospace Research Institute (KARI), which are currently operating: KOMPSAT-3, KOMPSAT-3A, and KOMPSAT-5 satellites. Our proposed model demonstrates superior performance compared to other SOTA baseline models. We demonstrate that our approach is 94.13% higher predictive performance than the second-best model in the KOMPSAT-3 dataset, 89.79% higher in the KOMPSAT-3A dataset, and 76.71% higher in the KOMPSAT-3 dataset.

Changrok So, Simon S. Woo , and Jong Hwan Ko
International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 2024
Online video detection becomes more challenging with higher resolution as computational costs increase proportionally with increasing resolution. To address this issue, we present a novel approach, DynaPP, which arranges object candidate regions into a compact form. DynaPP performs resource intensive whole-image inference only on sparse key frames, employing reduced resolutions for inference on other frames. Additionally, we propose transforming a 1-stage detector into a dynamic resolution model to facilitate frame inference at reduced resolutions. Here, the dynamic resolution model signifies a model capable of inferring all resolutions, distinguishing itself from typical models by not having restricted inferable resolutions. Unlike prior studies introducing new model structures for multi-resolution models, our work demonstrates that slight modifications to existing models can convert them to dynamic resolution models. DynaPP showcases substantial acceleration in video detection across four representative video datasets: AUAIR (5.5×), UAVDT (3.67×), VisDrone (2.73×), and ImageNet VID (3.69×), while maintaining a mean average precision with a small loss (≤2.2). Furthermore, we observed that our method achieves a detection acceleration of up to 8.84×, depending on the video clip.

Geonho Son†, Juhun Lee†, and Simon S. Woo*
The 33rd International Joint Conference on Artificial Intelligence (IJCAI), Jeju, 2024
BK Computer Science IF=4
The fabrication of visual misinformation on the web and social media has increased exponentially with the advent of foundational text-to-image diffusion models. Namely, Stable Diffusion inpainters allow the synthesis of maliciously inpainted images of personal and private figures, and copyrighted contents, also known as deepfakes. To combat such generations, a disruption framework, namely Photoguard, has been proposed, where it adds adversarial noise to the context image to disrupt their inpainting synthesis. While their framework suggested a diffusion-based approach, the disruption is not sufficiently strong and it requires a significant amount of GPU and time to immunize the context image. In our work, we re-examine both the minimal and favorable conditions for a successful inpainting disruption, proposing DDD, a “Digression guided Diffusion Disruption” framework. Firstly, we identify the most adversarially vulnerable diffusion imestep range with respect to the hidden space. Within this scope of noised manifold, we pose the problem as a semantic digression optimization. We maximize the distance between the inpainting instance’s hidden states and a semantic-aware hidden state centroid, calibrated both by Monte Carlo sampling of hidden states and a discretely projected optimization in the token space. Effectively, our approach achieves stronger disruption and a higher success rate than Photoguard while lowering the GPU memory requirement, and speeding the optimization up to three times faster.

Kangjun Lee, Inho Jung, and Simon S. Woo*
Deepfake detection research has been actively conducted in the past. While many deepfake detectors have been proposed, validating the practicality of such systems against real-world settings has not been explored much. Indeed, there might be gaps and disparities when they are applied in the real world. In this work, we developed a real time integrated web-based deepfake detection system, iFakeDetector, which incorporates the recent high performing deepfake detectors, and enables easy access for non-expert users to evaluate deepfake videos. Our system takes a deepfake video as input, allowing users to upload videos and select different detectors, and provides detection results on whether the uploaded video is a deepfake or not. Furthermore, we provide an analysis tool that enables the video to be analyzed on a frame-by-frame basis with the probability of each frame being manipulated. Finally, we tested and deployed iFakeDetector in a real-world scenario to verify its practicality and feasibility.

Binh M. Le and Simon S. Woo*
The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2024
BK Computer Science IF=4
Recent advancements in domain generalization (DG) for face anti-spoofing (FAS) have garnered considerable attention. Traditional methods have focused on designing learning objectives and additional modules to isolate domain-specific features while retaining domain-invariant characteristics in their representations. In this paper, we introduce GAC-FAS, a novel learning objective that encourages the model to converge towards an optimal flat minimum without necessitating additional learning modules. Unlike conventional sharpness-aware minimizers, GAC-FAS identifies ascending points for each domain and regulates the generalization gradient updates at these points to align coherently with empirical risk minimization (ERM) gradient updates. This unique approach specifically guides the model to be robust against domain shifts. We demonstrate the efficacy of GAC-FAS through rigorous testing on challenging cross-domain FAS datasets, where it establishes state-of-the-art performance.

Razaib Tariq, Minji Heo, Simon S. Woo* and Shahroz Tariq
WORKSHOP ON MEDIA FORENSICS (CVPR), Seattle, 2024
The detection of deepfakes is crucial for mitigating the societal impact of falsified video content. Despite the development of various algorithms for this purpose, challenges arise for detectors in real-world scenarios, especially when users capture deepfake content from screens and upload it online or when detectors operate on external devices like smartphones, requiring the capture of potential deepfakes through the camera for evaluation. A significant challenge in these scenarios is the presence of Moir ́e patterns, which degrade image quality and complicate conventional classification methods, notably deep neural networks (DNNs). However, the impact of Moir ́e patterns on the effectiveness of deepfake detection systems has not been adequately explored. This study aims to investigate how capturing deepfake videos via digital screen cameras affects the accuracy of detection mechanisms. We introduced the Moir ́e patterns by capturing the display of a monitor using a smartphone camera and conducted empirical evaluations using four widely recognized datasets: CelebDF, DFD, DFDC, and FF++. We compare the performance of twelve SOTA detectors on deepfake videos captured under the influence of Moir ́e patterns. Our findings reveal a performance decrease of up to 33.1 and 31.3 percentage points for image and video-based detectors. Therefore, highlighting the challenges posed by Moir ́e patterns and other naturally induced artifacts is critical for improving the effectiveness of real-world deepfake detection effort.

Simon S. Woo*
The Web Conference (WWW) (History of the Web Session), Singapore, 2024
(Short paper)
Since the inception of the Internet and WWW, providing the time among multiple nodes on the Internet has been one of the most critical challenges. David Mills is the pioneer to provide time on the Internet, inventing the Network Time Protocol (NTP), and synchronizing the clocks in computer systems. Now, the NTP is predominantly used on the Internet and WWW. In this paper, we revisit the NTP, and present the overview of the NTP. And, we highlight the advanced research effort, the SpaceNTP, to synchronize the clocks among space assets, which is the fundamental medium to provide the web services in space.

Sangup Lee and Simon S. Woo*
The 28th Pasific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Taiwan, 2024
BK Computer Science IF=1 (Oral Talk)
Our proposed method utilizes saliency detection, similar to anomaly detection, to identify the most significant region and effectively detect abnormal data. In this work, We propose a novel framework, Saliency-aware Anomaly Detection (SalAD), for detecting anomalies in multivariate time series data. SalAD comprises three main components: 1) a saliency detection module to remove redundant data, 2) an unsupervised saliency-aware forecasting model, and 3) a saliencyaware anomaly score to differentiate anomalies. We evaluate our model using the real-world Korea Aerospace Research Institute (KARI) orbital element dataset, which includes six orbital elements and unexpected disturbances from satellites, as well as conducting extensive experiments on four benchmark datasets to demonstrate its effectiveness and superiority over other baselines. The SalAD framework has been deployed on the K3A and K5 satellites.

Binh M. Le and Simon S. Woo*
The 28th Pasific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Taiwan, 2024
BK Computer Science IF=1 (Oral Talk) (Best Paper Running-up Award)
The primary goal of deep metric learning is to construct a comprehensive embedding space that can effectively represent samples originating from both intra- and inter-classes. Although extensive prior work has explored diverse metric functions and innovative training strategies, much of this work relies on default training data. Consequently, the potential variations inherent within this data remain largely unexplored, constraining the model's robustness to unseen images.In this context, we introduce the Spherical Embedding Expansion (dubbed SEE) method. SEE aims to uncover the latent semantic variations in training data. Especially, our method augments the embedding space with synthetic representations based on Max-Mahalanobis distribution (MMD) centers, which maximize the dispersion of these synthetic features without increasing computational costs.

Jeongho Kim and Simon S. Woo*
The 28th Pasific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Taiwan, 2024
BK Computer Science IF=1 (Oral Talk)
Although self-knowledge distillation shows remarkable performance improvement with fewer resources than conventional teacher-student based KD approaches, existing self-KD methods still require additional time and memory for training. We propose Relation-Aware Label Smoothing for Self-Knowledge Distillation (RAS-KD) that regularizes the student model itself by utilizing the inter-class relationships between class representative vectors with a light-weight auxiliary classifier. Compared to existing self-KD methods that only consider the instance-level knowledge, we show that proposed global-level knowledge is sufficient to achieve competitive performance while being extremely efficient training cost. Also, we achieve extra performance improvement through instance-level supervision.

Kishor Kumar Bhaumik, Fahim Faisal Niloy, Saif Mahmud, and Simon S. Woo*
The 28th Pasific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Taiwan, 2024
BK Computer Science IF=1 (Oral Talk)
We propose Spatio-Temporal Lightweight Graph GRU, namely STLGRU, a novel traffic forecasting model for predicting traffic flow accurately. Specifically, our proposed STLGRU can effectively capture dynamic local and global spatial-temporal relations of traffic networks using memory-augmented attention and gating mechanism in a continuously synchronized manner. Moreover, instead of employing separate temporal and spatial components, we show that our memory module and gated unit can successfully learn the spatial-temporal dependencies, with reduced memory usage and fewer parameters. Extensive experimental results on three real-world public traffic datasets demonstrate that our method can not only achieve state-of-the-art performance but also exhibit competitive computational efficiency.

Minha Kim, Kangjun Lee, Simon S. Woo* , and Youngho Jun
The 37th International Electric Vehicle Symposium & Exhibition (EVS37), Korea, 2024
The smart regenerative braking system for EV can reduce unnecessary brake operation by assisting in braking of the vehicle according to the driving situation, road slope, and driver’s preference. This system maintains the distance between the ego and front vehicles without controlling the brake pedal. Since the strength of regenerative braking is generally determined based on calibration data determined during the vehicle development process, some driver could suffer inconvenience when the regenerative braking is activated differently from their driving habits. In order to solve this problem, various deep learning-based algorithms are developed to provide driving stability by learning the driving data. Among those artificial intelligence algorithms, anomaly detection algorithms can successfully separate the deceleration data in abnormal driving situations, and the resulting refined deceleration data can be used to train the regression model to achieve better driving stability. In this study, we extensively compare and evaluate the performance of clustering and anomaly detection methods.

Fahim Faisal Niloy, Kishor Kumar Bhaumik, and Simon S. Woo*
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Korea, 2024
In this paper, we address source-free and online domain adaptation, i.e., test-time adaptation (TTA), for satellite im- ages subject to various forms of image degradation. Towards achieving this goal, we propose a novel TTA approach involv- ing two effective strategies. First, we progressively estimate the global Batch Normalization (BN) statistics of the target distribution with incoming data stream. Leveraging these statistics during inference has the ability to effectively reduce domain gap. Furthermore, we enhance prediction quality by refining the predicted masks using global class centers. Both strategies employ dynamic momentum for fast and stable convergence. Notably, our method is back-propagation-free and hence fast and lightweight, making it highly suitable for on-the-fly adaptation to new domain. Through comprehen- sive experiments across various domain adaptation scenarios, we demonstrate the robust performance of our method.

Seunghoo Hong†, Juhun Lee†, and Simon S. Woo*
The 38th Annual AAAI Conference on Artificial Intelligence (AAAI), Canada, 2024
BK Computer Science IF=4
Text-to-Image models such as Stable Diffusion have shown impressive image generation synthesis, thanks to the utilization of large-scale datasets. However, these datasets may contain sexually explicit, copyrighted, or undesirable content, which allows the model to directly generate them. Given that retraining these large models on individual concept deletion requests is infeasible, fine-tuning algorithms have been developed to tackle concept erasing in diffusion models. While these algorithms yield good concept erasure, they all present one of the following issues: 1) the semantics of the prompts change over time, 2) long and inefficient training exposes the model to more harm, and 3) the spatial structure distribution of each generated image is not preserved after fine-tuning. These issues severely degrade the original utility of generative models. In this work, we present a new approach that solves all of these challenges. We take inspiration from the concept of classifier guidance and propose a surgical update on the classifier guidance term while constraining the unconditional score term. Furthermore, our algorithm empowers the user to select an alternative to the erasing concept, allowing for more controllability. Our experimental results show that our algorithm not only erases the target concept effectively but also preserves the model’s generation capability.

Hyunjune Kim, Sangyong Lee, and Simon S. Woo*
The 38th Annual AAAI Conference on Artificial Intelligence (AAAI), Canada, 2024
BK Computer Science IF=4
In this work, we propose a fast and novel machine unlearning paradigm at the layer level called layer attack unlearning, which is highly accurate and fast compared to existing machine unlearning algorithms. We introduce the Partial-PGD algorithm to locate the samples to forget efficiently. In addition, we only use the last layer of the model inspired by the Forward-Forward algorithm for unlearning process. Lastly, we use Knowledge Distillation (KD) to reliably learn the decision boundaries from the teacher using soft label information to improve accuracy performance. We conducted extensive experiments with SOTA machine unlearning models and demonstrated the effectiveness of our approach for accuracy and end-to-end unlearning performance.

Hyunmin Choi, Simon S. Woo , and Hyoungshick Kim*
The 38th Annual AAAI Conference on Artificial Intelligence (AAAI), Canada, 2024
BK Computer Science IF=4
This paper introduces Blind-Touch, a novel machine learning-based fingerprint authentication system that leverages homomorphic encryption to address these privacy concerns. Homomorphic encryption allows for computations on encrypted data without decrypting it. Therefore, Blind-Touch can keep fingerprint data encrypted on the server while performing machine learning operations. Blind-Touch integrates three techniques to address the computational challenges of using homomorphic encryption for machine learning: (1) A distributed machine learning architecture that divides inference tasks between the client and server, thereby reducing encrypted computations on the server; (2) A data compression method that reduces client-server communication costs; and (3) A cluster architecture that improves scalability with the number of registered users. Blind-Touch achieves high accuracy on two benchmark fingerprint datasets, with a 93.6% F1-score for the PolyU dataset and a 98.2% F1-score for the SOKOTO dataset. Moreover, Blind-Touch can match a fingerprint among 5,000 in about 0.65 seconds.With its privacyfocused design, high accuracy, and efficiency, Blind-Touch is a promising alternative to conventional fingerprint authentication for web and cloud applications.

Eldor Abdukhamidov, Mohammed Abuhamad, Simon S. Woo, Eric Chan-Tin, and Tamer ABUHMED
IEEE Transactions on Dependable and Secure Computing (SCIE, IF=6.8, Q1), 2024
This work introduces two attacks, AdvEdge and AdvEdge+, which deceive both the target deep learning model and the coupled interpretation model. We assess the effectiveness of proposed attacks against four deep learning model architectures coupled with four interpretation models that represent different categories of interpretation models. Our experiments include the implementation of attacks using various attack frameworks. We also explore the attack resilience against three general defense mechanisms and potential countermeasures. Our analysis shows the effectiveness of our attacks in terms of deceiving the deep learning models and their interpreters, and highlights insights to improve and circumvent the attacks.

Daeyoung Yoon, Yuseung Gim, and Eunseok Park, Simon S. Woo*
The 39th ACM/SIGAPP Symposium On Applied Computing (SAC), Avila, Spain, 2024
BK Computer Science IF=1
We propose a novel framework called Reinforced Adversarial Anomaly Detector (RAAD) based on Reinforcement Learning to mine and detect anomalies or attacks in the presence of very few attack or anomaly patterns in time-series. Our approach uses two adversarial agents, where one agent acts as an attacker and the other as a defender. The attacker agent learns a policy to disturb the defender agent by effectively sampling the defender’s worst-performing trajectories from synthetically generated states provided by the environment, while the defender agent learns a policy that can distinguish between the normal and abnormal (attack) states. Upon successful training of two adversarial policies, the defender agent can effectively evaluate whether a new observation follows the distribution of normal states. In particular, RAAD overcomes the inherent overfitting issue, which other approaches have, through adversarial training and Reinforcement Learning. Using multiple real-world anomaly and attack detection datasets, we demonstrate that RAAD outperforms the several other baseline approaches in identifying abnormal patterns.

Girim Ban, and Simon S. Woo*
The 39th ACM/SIGAPP Symposium On Applied Computing (SAC), Avila, Spain, 2024
BK Computer Science IF=1
We present a data-driven model, the Action Attention bidirectional Gated Recurrent Unit (AAGRU) to effectively learn sequences of user behaviors without explicit knowledge of the actors or targets for conversion prediction. Tailored to predict impending purchases based on ADID’s customer journey, AAGRU leverages two pivotal components: the Action Block and the Interval Block. The former adeptly captures salient actions in the journey through attention mechanisms, while the latter discerns temporal nuances, such as impulse and deliberate buying tendencies. This tailored approach enables digital marketing agencies to identify latent customers primed for purchase, thus optimizing targeted advertising and conversion strategies. Our experimental results affirm AAGRU’s superiority over extant deep learning models. Significantly, in simulations, AAGRU demonstrated impressive performance against our company’s best audience group.

Gwanghan Lee, Saebyeol Shin, Taeyoung Na and Simon S. Woo*
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, Hawaii, 2024
We propose a novel efficient ViT architecture for real-time interactive colorization, AdaColViT determines which redundant image patches and layers to reduce in the ViT. Unlike existing methods, our novel pruning method alleviates performance drop and flexibly allocates computational resources of input samples, effectively achieving actual acceleration. In addition, we demonstrate through extensive experiments on ImageNet-ctest10k, Oxford 102flowers, and CUB-200 datasets that our method outperforms the baseline methods.

Lee, S., Kim, S., Chu, Y. Choi, J., Park, E.* and Simon S. Woo
IEEE Transactions on Computational Social Systems (SCIE, IF=5.0, Q1), 2024
With the growing ubiquity and broad usage, emojis are widely used as a universal visual language, which complements the intentions and emotions beyond the textual data. Despite the critical role of representing emotion, existing emojis neglect the subtle and complex properties of human emotion in that only countable and finite face emojis exist in a categorical manner. In this article, we propose a novel approach to facial emoji generation, which can control the emotional degree of generated emojis for more complex and detailed usage on online conversations. In other words, we develop a new emotion aware emoji generative adversarial network, which is capable of generating an emoji that expresses a given emotion distribution. In this way, our approach aims to map fine grained emotions to expressive emojis. Both quantitative and qualitative evaluation demonstrate that our approach can successfully generate high quality emoji like images by representing a wide range of emo tions. To the best of our knowledge, this is the first approach to use the deep generative model from the standpoint of the emoji’s emotional role, which can further promote more interactive and effective online communication.

2023
Giljun Lee, Junyaup Kim, Gwanghan Lee and Simon S. Woo*
This paper proposes E^2RDet. This algorithm effectively modifies the structure of the Yolov7 object detection model, enabling it to accurately detect objects represented by oriented bounding boxes (OBB) in SAR images. This algorithm improves the object detection model architecture and loss function to facilitate learning of an object's dynamic (orientation) posture. Using various training datasets, E^2RDet demonstrates performance improvements across three benchmark SAR datasets. This indicates that existing HBB object detection models can train and perform object detection on objects represented by OBBs.

Chingis Oinar†, Binh M. Le†, and Simon S. Woo*
SCIE Q1 IF=3.47
Imbalanced learning might include both classes having different learning difficulties or different numbers of available training samples. We hypothesize that it significantly affects the generalization ability of the deep face models. Inspired by this, we introduce a novel adaptive strategy, called KappaFace, to modulate the relative importance based on class learning difficulty and its imbalance. Due to the von Mises-Fisher distribution, our proposed KappaFace loss can intensify margins for difficult-to-learn or under-represent classes while relaxing that of counter classes. Experiments conducted on popular facial benchmarks demonstrate that our proposed method achieves superior performance to the state-of-the-art methods.

Seung-yeon Back, Eun-Ju Park, and Simon S. Woo*
Large Language Models' Interpretation and Trustworthiness (CIKM 2023) Workshop
In our study, we turn our attention specifically to the bias issues at the intersection of gender and occupations within LLM-generated text. Our research seeks to address this concern by examining how gender bias is reflected in responses generated by LLMs, with a focus on the fields of gender and occupation. We aim to explore these biases not only in English, but also in Korean language, thereby expanding the scope of our investigation to different linguistic and cultural contexts. Through these investigations, our research aims to provide a comprehensive comparison of bias patterns across different languages and cultures. Ultimately, we seek to contribute to the ongoing dialogue surrounding ethical concerns in LLMs and offer implications for future developments in the field of natural language processing.

Shahroz Tariq, Daewon Chung, Simon S. Woo* and Youjin Shin
Workshop
In recent times, there has been a notable surge in the amount of vision and sensing/time-series data obtained from drones and satellites. This data can be utilized in various fields, such as precision agriculture, disaster management, environmental monitoring, and others. However, the analysis of such data poses significant challenges due to its complexity, heterogeneity, and scale. Furthermore, it is critical to identify anomalies and maintain/monitor the health of drones and satellite systems to enable the aforementioned applications and sciences. This workshop presents an excellent opportunity to explore solutions that specifically target the detection of anomalies and novel occurrences in drones and satellite systems and their data. The workshop is designed to promote knowledge exchange, collaboration, and innovation in Anomaly and Novelty detection for Satellite and Drone systems. Through this platform, researchers, practitioners, and industry experts are expected to come together to explore and discuss the latest developments, challenges, and opportunities in analyzing and maintaining the health of drone and satellite systems, in addition to detecting anomalies and novelties in the associated vision and time-series data. The primary objective of the workshop is to facilitate in-depth discussions on various techniques, methodologies, and applications related to anomaly and novelty detection. Participants will be encouraged to share their ideas and experiences on how best to identify new research directions and potential collaborations. Ultimately, the workshop aims to enhance the capabilities of leveraging drone and satellite systems for diverse applications such as precision agriculture, disaster management, and environmental monitoring. By the end of the workshop, participants are expected to gain valuable insights into state-of-the-art approaches and establish connections with peers. This will provide an opportunity for them to contribute to the advancement of knowledge in this domain, leading to more efficient and effective utilization of drone and satellite systems. For more information, visit our website at ANSD'23

Eun-Ju Park, Seung-Yeon Back, Jeongho Kim, and Simon S. Woo*
32nd ACM International Conference on Information & Knowledge Management (CIKM), UK, 2023
Resource Paper
To mitigate the risks associated with fraudulent ID card verification, we present a novel dataset for classifying cases where the ID card images that users upload to the verification system are genuine or digitally represented. Our dataset is replicas designed to resemble real ID cards, making it available while avoiding privacy issues. Through extensive experiments, we demonstrate that our dataset is effective for detecting digitally represented ID card images, not only in our replica dataset but also in the dataset consisting of real ID cards.

Sangyong Lee and Simon S. Woo*
32nd ACM International Conference on Information & Knowledge Management (CIKM), UK, 2023
BK Computer Science IF=2 (Short Paper)
In this work, we propose a novel two-step unlearning approach UNDO. First, we selectively disrupt the decision boundary of forgetting data at the coarse-grained level. However, this can also inadvertently affect the decision boundary of other remaining data, lowering the overall performance of classification task. Hence, we subsequently repair and refining the decision boundary for each class at the fine-grained level by introducing a loss for maintain the overall performance, while completely removing the class. We conducted extensive experiments with SOTA models over two datasets, and demonstrated the effectiveness and efficiency of our approach for unlearning, compared to other methods.

Juho Jung, Chaewon Kang, Jeewoo Yoon, Simon S. Woo, and Jinyoung Han
32nd ACM International Conference on Information & Knowledge Management (CIKM), UK, 2023
BK Computer Science IF=2 (Short Paper)
This paper proposes a novel sequential attentive face embedding, SAFE, that can capture facial dynamics in a deepfake video. The proposed SAFE can effectively integrate global and local dynamics of facial features revealed in a video sequence using contrastive learning. Through a comprehensive comparison with the state-of-the-art methods on the DFDC (Deepfake Detection Challenge) dataset and the FaceForensic++ benchmark, we show that our model achieves the highest accuracy in detecting deepfake videos on both datasets.

Beomsang Cho†, Binh M. Le†, Jiwon Kim,Simon S. Woo* , Shahroz Tariq, Alsharif Abuadbba, and Kristen Moore
32nd ACM International Conference on Information & Knowledge Management (CIKM), UK, 2023
BK Computer Science IF=3 (Full Paper)
Our contributions in this IRB-approved study are to bridge this knowledge gap from current real-world deepfakes by providing in-depth analysis.We first present the largest and most diverse and recent deepfake dataset (RWDF-23) collected from the wild to date, consisting of 2,000 deepfake videos collected from 4 platforms targeting 4 different languages span created from 21 countries: Reddit, YouTube, TikTok, and Bilibili. By expanding the dataset's scope beyond the previous research, we capture a broader range of real-world deepfake content, reflecting the ever-evolving landscape of online platforms. Also, we conduct a comprehensive analysis encompassing various aspects of deepfakes, including creators, manipulation strategies, purposes, and real-world content production methods. This allows us to gain valuable insights into the nuances and characteristics of deepfakes in different contexts. Lastly, in addition to the video content, we also collect viewer comments and interactions, enabling us to explore the engagements of internet users with deepfake content.

Binh M. Le and Simon S. Woo*
IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023
BK Computer Science IF=4
In this work, we propose a universal intra-model collaborative learning framework to enable the effective and simultaneous detection of different quality of deepfakes. That is, our approach is the quality-agnostic deepfake detection method, dubbed QAD. In particular, by observing the upper bound of general error expectation, we maximize the dependency between intermediate representations of images from different quality levels via Hilbert-Schmidt Independence Criterion. In addition, an Adversarial Weight Perturbation module is carefully devised to enable the model to be more robust against image corruption while boosting the overall model’s performance. Extensive experiments over seven popular deepfake datasets demonstrate the superiority of our QAD model over prior SOTA benchmarks.

Hakjun Moon, Eunju Park, Jeongho Kim, Kwansik Yoon, Yeonah Seo, and Simon S. Woo*
2023 한국정보보호학회 하계학술대회 (우수논문상 Link)
2023 한국정보보호학화 하계학술대회 딥러닝 기반 신원 인증 시스템에 대해 제시하였으며, 비대면 상황에서 주민등록증이나 운전면허증과 같은 신분증의 진위를 확인하는 문제에 집중하였다. 딥러닝과 특징 추출 기법을 이용하여 신분증 이미지가 실물인지, 혹은 디지털 방식으로 조작되었는지 판별하도록 모델을 학습하였으며, 최대 96.6%의 높은 분류 정확도를 보였다. 이런 결과는 신원 인증과 보안의 중요성이 갈수록 부각되는 현재 사회에서 중요한 의미를 가진다.

Song-Chan Jin and Simon S. Woo*
본 논문에서 제안하는 선택적 망각이란 딥러닝 모델이 일부 지식을 선택적으로 잊어버리는 것을 의미하며, 개인정보 보호를 위해 도입되었다. 이를 위해 데이터 재수정 및 모델 재학습 등의 방법이 있지만, 이러한 방법들은 일반적으로 계산량이 많거나 모델의 성능을 크게 저하시키는 문제가 있어서 이에 대한 대안으로 작은 데이터셋으로 다른 데이터들에 대한 지식은 유지한 채 특정 데이터들에 대한 지식만 잊는 경사 상승법을 소개하고 있다. 본 논문에서는 경사 상승법을 통하여 기존 재학습 기법 대비 9배 적은 계산량으로 선택적 망각을 수행할 수 있다는 결과를 얻었다.

Fahim Faisal Niloy, Kishor Kumar Bhaumik, and Simon S. Woo*
IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Oct. 2023
Existing high-resolution satellite image forgery localization methods rely on patch-based or downsampling-based training. Both of the training methods have major drawbacks, such as, inaccurate boundary between pristine and forged region, generation of unwanted artifacts, etc. To tackle aforementioned challenges, inspired from the high-resolution image segmentation literature, we propose a novel model called HRFNet to effectively enable satellite image forgery localization. Specifically, equipped with shallow and deep branches, our model can successfully integrate RGB and resampling features in both global and local manner to localize forgery more accurately. We experiment on popular satellite image manipulation dataset to demonstrate that our method achieves the best performance, while the memory requirement and processing speed are not compromised compared to existing methods.

Chingis Oinar, Binh M. Le, and Simon S. Woo*
SCIE Q1 IF=3.47
In this work, we explain and propose a novel self-supervised objective, Expectation-Maximization via Pretext-Invariant Representations (Empir), which enhances Expectation-Maximization-based optimization in BYOL-like algorithms by enforcing augmentation invariance within a local region of k nearest neighbors, resulting in consistent representation learning. In other words, we propose Expectation-Maximization as a core task of asymmetric architectures. We show that it consistently outperforms other SOTA algorithms by a decent margin. We also demonstrate its transfer learning capabilities on downstream image recognition tasks.

Jeongho Kim, Hanbeen Lee, and Simon Woo
The 32nd International Joint Conference on Artificial Intelligence (IJCAI), Macao, August 2023
BK Computer Science IF=4
In this work, to address the student model's limitation, we propose a novel flexible KD framework, Integrating Matched Features using Attentive Logit in Knowledge Distillation (IMF). Our approach introduces an intermediate feature distiller (IFD) to improve the overall performance of the student model by directly distilling the teacher's knowledge into branches of student models.The generated output of IFD, which is trained by the teacher model, is effectively combined by attentive logit.We use only a few blocks of the student and the trained IFD during inference, requiring an equal or less number of parameters.Through extensive experiments, we demonstrate that IMF consistently outperforms other state-of-the-art methods with a large margin over the various datasets in different tasks without extra computation.

F.F Nioy, Kishor Bhaumik, and Simon S. Woo
The 2nd Workshop on the security implications of Deepfakes and Cheapfakes (WDC'23)
Deepfake videos are mostly generated in a frame-by-frame manner, which leaves visible object-level inconsistencies in both temporal and spatial dimensions. In this paper, we propose a novel deepfake video detection method that exploits this important clue. Specifically, we extract object representations using vision transformers from video frames and then model the object-level coherence in both intra-frame and inter-frame manner. We experiment on benchmark dataset to show that our method outperforms several existing methods in deepfake video detection.

Binh Le, Shahroz Tariq, Alsharif Abuadbba, Kristen Moore, and Simon S. Woo
The 2nd Workshop on the security implications of Deepfakes and Cheapfakes (WDC'23)
Recent rapid advancements in deepfake technology have allowed the creation of highly realistic fake media, such as video, image, and audio. These materials pose significant challenges to human authentication, such as impersonation, misinformation, or even a threat to national security. To keep pace with these rapid advancements, several deepfake detection algorithms have been proposed, leading to an ongoing arms race between deepfake creators and deepfake detectors. Nevertheless, these detectors are often unreliable and frequently fail to detect deepfakes. This study highlights the challenges they face in detecting deepfakes, including (1) the pre-processing pipeline of artifacts and (2) the fact that generators of new, unseen deepfake samples have not been considered when building the defense models. Our work sheds light on the need for further research and development in this field to create more robust and reliable detectors.

Shahzeb Tariq, Shahroz Tariq, SangYoun Kim, Simon S. Woo, and Chang Kyoo Yoo
Journal of Sustainable Cities and Society
(Accepted) SCIE IF = 10.696
Rapid urbanization and economic growth have increased air pollution, threatening human health and life expectancy, especially in developing nations. Strong air quality early warning systems for city sustainability have recently garnered attention. The present early warning frameworks in urban environments can only forecast air quality where sufficient sensor data is available. We propose a spatiotemporal sensor fusion-based distance adaptive graph convolutional gated network that predicts primary pollutants at multiple megacity locations and temporal horizons. Our remotely forecasted concentrations at a sensorless site matched city air quality distribution. The framework also solves critical problems of early warning systems related to long-term sensor failure and prediction at a new location in the city.

Siwon Huh, Myungkyu Shim, Jihwan Lee, Simon S. Woo, Hyoungshick Kim, and Hojoon Lee
IEEE Transactions on Dependable and Secure Computing (TDSC)
SCIE IF = 7.32 (Jan 2023)
Decentralized Identity (DID) is emerging as a new digital identity management scheme that promises users complete control of their personal data and identification without central authority involvement. The World Wide Web Consortium (W3C) has drafted the DID standard and provided reference implementations. We conduct a security analysis of the W3C DID standard and the reference universal resolver implementation, focusing on user privacy in the DID resolving process. The universal resolver is the key component in the architecture that processes DID requests and DID document retrievals. Our analysis demonstrates that privacy issues can arise due to the imprudent design of the universal resolver. Furthermore, we found that side-channels in the DID document caching schemes of real-world DID services can entail privacy concerns. Motivated by our security analysis, we present a novel DID resolving design, called Oblivira, to enable obliviously DID resolving. Oblivira is a secure resolving agent with a small footprint that enforces the universal resolver to resolve requests without knowing their content. We also propose a privacy-preserving DID document caching scheme that eliminates side-channels. Our evaluation results show that Oblivira only incurs approximately 2.6\% of overhead on average with different resolver settings (3, 6, and 12 threads).

Shahroz Tariq, Sowon Jeon, and Simon S. Woo*
IEEE Computer Magazine
SCIE IF = 3.56 (May 2023)
Deep learning algorithms enable rapid growth in web-based services such as natural language processing, speech recognition, and facial recognition. Simultaneously, online fairness and trust remain unresolved. For example, racial bias in web-based face recognition services can lead to inaccurate results, causing severe technical and social issues and widespread distrust in AI-based systems. Deepfake on social media has posed several credibility issues. We evaluate the racial bias in face recognition APIs using real and deepfake celebrity images. We use deepfake generation methods to introduce small, imperceptible changes to the real images to shift the racial class of predictions. As a result, we show how deepfake images exacerbated racial bias in Amazon, Microsoft, and Naver web-based face recognition APIs. The findings are significant because they reveal similar vulnerabilities to those previously discovered through adversarial attacks but through a significantly different method.

Sowon Jeon, Gilhee Lee, Hyoungshick Kim, and Simon S. Woo*
Data Mining and Knowledge Discovery
(Accepted) SCIE IF = 3.67
In this paper, we present SmartConDetect as a tool for detecting security vulnerabilities in Solidity smart contracts. SmartConDetect is a static analysis tool that extracts code fragments from Solidity smart contracts and uses a pre-trained BERT model to find susceptible code patterns. To demonstrate the performance of SmartConDetect, we use two public datasets, and our dataset (SmartConDataset) collected from the real-world Ethereum blockchain network. Our experimental results show that SmartConDetect significantly outperforms all state-of-the-art methods, achieving 90.9\% F1-score when using our own dataset. Specifically, SmartConDetect is about 2 times faster than SmartCheck in detection. Furthermore, we conduct a real-world case study to analyze the distribution of detected vulnerabilities.

Gwanghan Lee, Saebyeol Shin, Donggeun Ko, Jiyeon Jung, and Simon Woo*
The 2nd International Workshop on Practical Deep Learning in the Wild at AAAI, 2023.
Vision transformer has been used to alleviate this problem by using multi-head self attention to propagate user hints to distant relevant areas in the image. However, despite the success of vision transformers in colorizing the image and selectively colorizing the regions with user propagation hints, heavy underlying ViT architecture and the large number of required parameters hinder active real-time user interaction for colorization applications. Thus, in this work, we propose a novel efficient ViT architecture for real-time interactive colorization, A-ColViT that adaptively prunes the layers of vision transformer for every input sample. This method flexibly allocates computational resources of input samples, effectively achieving actual acceleration. In addition, we demonstrate through extensive experiments on ImageNet-ctest10k, Oxford 102flower, and CUB-200 datasets that our method outperforms the state-of-the-art approach and achieves actual acceleration.

Geunsu Kim, Gyudo Park, Soohyeok Kang, and Simon Woo*
The 38th ACM/SIGAPP Symposium On Applied Computing, Tallinn, Estonia, March, 2023
BK Computer Science IF=1
In this work, we propose a Sparse Vision Transformer (S-ViT) based on the Vision Transformer (ViT) architecture to improve the face recognition tasks. After the model is trained, S-ViT tends to have a sparse distribution of weights compared to ViT, so we named it according to these characteristics. Unlike the conventional ViT, our proposed S-ViT adopts image Relative Positional Encoding (iRPE) method for positional encoding. Also, S-ViT has been modified so that all token embeddings, not just class token, participate in the decoding process. Through extensive experiment, we showed that S-ViT achieves better performance in closed-set than the other baseline models, and showed better performance than the baseline ViT-based models. We also show that the use of ArcFace loss functions yields greater performance gains in S-ViT than in baseline models. In addition, S-ViT has an advantage in cost-performance trade-off because it tends to be more robust to the pruning technique than the underlying model, ViT. Therefore, S-ViT offers the additional advantage, which can be applied more flexibly in the target devices with limited resources.

Jeongho Kim†, Yungyoo Lee†, Donggeun Ko, Taejun Kim, Sooyoun Ham, and Simon Woo*
The 38th ACM/SIGAPP Symposium On Applied Computing, Tallinn, Estonia, March, 2023
BK Computer Science IF=1 (Best Paper Award)
Medical images, including computed tomography (CT) assist doctors and physicians in diagnosing anatomic structures and various internal pathologies. In CT, intravenous contrast media is often applied, which are chemicals developed to aid in the characterization of pathology by enhancing the capabilities of an imaging modality to differentiate between different biological tissues. Especially, with the use of contrast media, thorough examinations of the patients can be possible. However, contrast media can have severe adverse and side effects such as hypersensitive reaction to generalized seizures. Yet, without contrast media, it is difficult to diagnose patients that have disorders in the internal organs. With the help of DNN models, especially generative adversarial network (GAN), contrast-enhanced CT (CECT) images can be synthetically generated from non-contrast CT (NCCT) images. GANs or autoencoder-based models have been proposed to generate contrast-enhanced CT images; however, the synthesized image does not fully reflect and have crucial spots where contrast has not been synthesized. Thus, in order to enhance the quality of the CECT image, we propose MGCMA, a multi-scale generator with a channel-wise mask attention module for generating synthetic CECT images from NCCT images. Our extensive experiments demonstrate that our model outperforms other baseline models in various metrics such as SSIM and LPIPS. Also, generated images from our approach achieve plausible outcomes from the domain experts' (e.g., physicians and radiologists) evaluations.

Jinbeom Kim†, Giljun Lee†, Taejun Kim, and Simon Woo*
The 38th ACM/SIGAPP Symposium On Applied Computing, Tallinn, Estonia, March, 2023
BK Computer Science IF=1
Oriented object detection in aerial images is a challenging task due to the highly complex backgrounds and objects with arbitrary oriented and usually densely arranged. Existing oriented object detection methods adopt CNN-based methods, and they can be divided into three types: two-stage, one-stage, and anchor-free methods. All of them require non-maximum suppression (NMS) to eliminate the duplicated predictions. Recently, object detectors based on the transformer remove hand-designed components by directly solving set prediction problems via performing bipartite matching, and achieve state-of-the-art performances in general object detection. Motivated by this research, we propose a transformer-based oriented object detector named Rotated DETR with oriented bounding boxes (OBBs) labeling. We embed the scoring network to reduce the tokens corresponding to the background. In addition, we apply a proposal generator and iterative proposal refinement in order to provide proposals with angle information to the transformer decoder. Rotated DETR achieves state-of-the-art performance on the single-stage and anchor-free oriented object detectors on DOTA, UCAS-AOD, and DIOR-R datasets with only 10\% feature tokens. In the experiment, we show the effectiveness of the scoring network and iterative proposal refinement.

Seonghye Jeong, Seongmoon Jeong, Simon Woo*, and Jong HwanKo
Pattern Recognition Letters SCIE Q1 IF=5.67 (Jan 2023)
An increasing amount of captured images are streamed to a remote server or stored in a device for deep neural network (DNN) inference. In most cases, raw images are compressed with encoding algorithms such as JPEG to cope with resource limitations. However, the standard JPEG optimized for human visual systems may induce significant accuracy loss in DNN inference tasks. In addition, the standard JPEG compresses all regions in an image at the same quality level, while some areas may not contain valuable information for the target task. In this paper, we propose a target-driven JPEG compression framework that performs region-adaptive quantization of the DCT coefficients. The region-based quality map is generated from an end-to-end trainable neural network. In addition, we present a deep learning approach to remove the requirement of storing the overhead information induced by the region-based encoding process. Our framework can be easily implemented on devices with commonly used JPEG and also produce images that achieve a higher compression rate with minimum degradation of the classification accuracy.

F.F. Niloy, Kishor Bhaumik, and Simon Woo*
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, Hawaii, 2023
Conventional forgery localizing methods usually rely on different forgery footprints such as JPEG artifacts, edge inconsistency, camera noise, etc., with cross-entropy loss to locate manipulated regions. However, these methods have the disadvantage of over-fitting and focusing on only a few specific forgery footprints. On the other hand, real-life manipulated images are generated via a wide variety of forgery operations and thus, leave behind a wide variety of forgery footprints. Therefore, we need a more general approach for image forgery localization that can work well on a variety of forgery conditions. A key assumption in underlying forged region localization is that there remains a difference of feature distribution between untampered and manipulated regions in each forged image sample, irrespective of the forgery type. In this paper, we aim to leverage this difference of feature distribution to aid in image forgery localization. Specifically, we use contrastive loss to learn mapping into a feature space where the features between untampered and manipulated regions are well-separated for each image. Also, our method has the advantage of localizing manipulated region without requiring any prior knowledge or assumption about the forgery type. We demonstrate that our work outperforms several existing methods on three benchmark image manipulation datasets.

2022
Jinbeom Kim, Giljun Lee, Taejune Kim, and Simon Woo*
매우 복잡한 배경과 임의로 회전 되어있고 조밀하게 배열되어 잇는 객체로 인해 항공 이미지에서 회전된 객체를 탐지하는 것은 매우 어려운 작업이다. 기존의 회전 객체 탐지 기법들은 CNN 기반 방법론을 채택하고 있으며, 이들은 세가지 카테고리 two-stage, one-stage, 그리고 anchor-free로 분류할 수 있다. 이들 모두 중복된 예측을 제거하기 위해 비최대 억제(NMS)가 필요하다. 최근 transformer를 기반으로 한 객체 탐지 모델은 이분 매칭을 통해 set prediction proble을 직접 해결하여 수작업으로 설계된 구성 요소들을 제거하면서 일반적인 객체 탐지 분야에서 최첨단 성능을 달성하였다. 이 연구에 자극을 받아, 우리는 방향 경계 상자(OBB) 라벨을 사용하는 transformer 기반 모델인 Rotated DETR를 제안한다.또한 우리는 proposal generator와 iterative proposal refinement를 적용하여 transformer decoder에 각도 정보를 제공한다. Rotated DETR은 10%의 feature token 만으로 DOTA 데이터 세트의 one-stage와 anchor-free 모델들에서 최첨단 성능을 달성한다. 우리는 실험을 통해 scoring network와 iterative proposal refinement의 효과를 보여준다.
Saebyeol Shin and Simon Woo*
다양한 딥페이크 데이터셋에 대한 최신 딥페이크 탐지 모델은 놀라운 성능을 달성했습니다. 그러나 대부분의 접근 방식은 각 딥페이크 입력 이미지가 서로다른 지역적인 부분에서 구별되는 특징을 가지고 있다는 사실을 활용하지 않습니다. 따라서 본 논문은 입력 이미지의 서로 다른 세부적인 부분에 동적으로 초점을 맞추고 실제 이미지와 딥페이크 이미지의 미묘하고 세부적인 차이를 이용하는 효과적인 딥페이크 탐지 방법인 MaskDF를 제안합니다. 특히 중요하지 않은 특성을 제거하여 입력의 귀중한 정보를 보존할 수 있는 학습 가능한 어텐션 마스크를 제안합니다. 입력 피쳐는 제안된 게이팅 함수를 통과하여 어텐션 마스크 벡터를 생성하므로 딥페이크 탐지에 영향을 미치는 중요한 특징을 결정할 수 있습니다. 우리의 방법은 입력 정보의 절반만 사용하여 DFDC 및 FaceForensics++ 데이터 세트에서 다른 기본 모델보다 더 나은 성능을 보여주었습니다.
Donggeun Ko and Simon Woo*
소셜 미디어나 감시 시스템에서 매일 수많은 얼굴 사진과 개인 정보가 수집된다. 얼굴 정보를 포함한 소셜 미디어 사용자의 개인 정보는 간단한 거래나 공항 출입국 절차의 간소화와 같은 이점이 있지만 이러한 이점은 항상 개인 정보 보호 문제를 수반한다. 위와 같은 민감한 정보들은 잠재적으로 유해한 목적으로 사용될 위험이 있기때문에 공격자에게 취약하다고 할 수 있다. 이러한 정보를 보호하기 위해 이미지의 프라이버시를 강화하는 솔루션인 DP(Differential Privacy)를 사용하여 높은 수준의 프라이버시를 제공한다. DP(Differential Privacy)를 통해 이미지의 프라이버시가 증가할 수 있지만 이상적인 epsilon-DP를 달성하기 위해서 유틸리티와 프라이버시 사이에는 필연적인 trade-off가 있다. 따라서 난독화 이미지의 최적 매개변수를 선택하는 것이 개인정보 보호의 핵심이며 본 논문에서는 이미지의 프라이버시를 강화하기 위해 각각 DP-Pix, DP-SVD, Snow라는 3가지 DP(Differential Privacy) 난독화 방법을 제시한다. 또한 딥 러닝 모델의 견고성을 평가하는 딥페이크 이미지 데이터셋에서 DP 방법을 구현하는 다양한 방법을 시연한다. 실험의 결과는 훈련 단계에서 데이터 세트 증대가 epsilon-DP(Differential Privacy를 사용하여 딥페이크를 탐지할 때 모델의 성능을 쉽게 향상시킬 수 있음을 나타낸다.
Donggeun Ko and Simon Woo*
최근들어 딥페이크(Deepfake) 기술의 발전으로 인해 국제사회의 우려가 점점 커지고 있다. 딥페이크 기술은 이미지나 영상 속 얼굴을 손쉽게 생성, 조작하여 왜곡된 정보를 전파할 수 있기 때문이다. 이에 따라 최첨단 성능을 갖춘 다양한 딥페이크 탐지 모델이 제안되어 왔다. 그러나 지금까지 제안된 딥페이크 탐지 모델은 펜데믹 위기 동안 발생했을 마스크가 착용된 얼굴에 대한 정보는 고려하지 않고 있다. 마스크가 착용된 얼굴 이미지의 경우 얼굴의 중요한 랜드마크가 마스크 속에 숨겨져 있기 때문에 딥페이크 탐지기의 성능을 보장하기 어렵다. 따라서 본 논문에서는 이러한 문제를 해결할 수 있는 두 가지 간단한 방법론을 제시하고 기존 방법론들과의 비교실험을 통해 마스크가 착용된 얼굴 이미지와 마스크가 착용되지 않은 얼굴 이미지 사이에서 나타날 수 있는 딥페이크 탐지 모델의 문제점과 제시된 방법론의 효과를 살펴보고자 한다.
Jinyong Park, Minha Kim, and Simon Woo*
AVSS: Advanced Video and Signal-Based Surveillance
BK Computer Science IF=1 (BKCSA149)
Super-resolution (SR) aims to recover the highresolution (HR) images from low-resolution (LR) images. Recently, various attempts, e.g., unsupervised SR models and domain-specific SR have achieved outstanding performance for various real-world applications. However, they significantly suffer from low generalization performance when trained on another domain dataset. Furthermore, they often exhibit performance degradation when the model continually learns multiple tasks; so-called catastrophic forgetting degrades the SR performance. In this paper, we are the first to propose a novel approach for continual multi-task SR named Replay-based Continual Representation Learning framework that can be applicable to GAN-based SR models, which utilizes feature memory for preserving the learned features from the previous task. Our experimental results demonstrate the effectiveness of RCRL in continual multi-task SR at improving generalization performance and alleviating catastrophic forgetting.

Kyunghee Kim, Minha Kim, and Simon Woo*
CIKM22-PAS: The 1st International Workshop on Privacy Algorithms in Systems, Georgia, USA, 2022
As time series data is collected and used in a variety of fields, the importance of preserving privacy on time series is also on the increase. This paper is a preliminary study of the Differential Privacy (DP) algorithm specially designed to provide privacy to time series data by integrating the time series decomposition technique. In particular, this study extends the Fourier Perturbation Algorithm (FPA) with Seasonal and Trend decomposition using LOESS (STL). In this work, we propose STL-DP, which first performs STL decomposition to the original data. Then we apply the FPA only to the core part of the time series, particularly trend or seasonal components, to provide privacy. In this preliminary study, we show that our approach consistently outperforms other baselines in terms of utility according to the experimental results.

Jaeju An, Taejun Kim, Donggeun Ko, Sangyup Lee, and Simon Woo*
The 16th Asian Conference on Computer Vision (ACCV2022), Macau SAR, China, 2022
BK Computer Science IF=1
The trained networks can often suffer from overfitting issues due to the unintended bias in a dataset causing inaccurate, unreliable, and untrustworthy results. To tackle this problem, we propose a novel augmentation framework, Adaptive Augmentation (A^2), based on a generative model and few-shot adaptation for augmenting bias-conflict samples that help classifiers learn debiased representations without any prior knowledge about bias types. Our framework consists of three steps: 1) extracting bias-conflict samples from a biased dataset in an unsupervised manner, 2) training a generative model with the biased dataset and adapting biased distribution from the generative model to the extracted bias-conflict samples' distribution, and 3) augmenting bias-conflict samples by translating bias-align samples with the trained generative model. Therefore, our classifier can effectively learn the debiased representation without human supervision.

Mirae Kim and Simon Woo*
Information has exploded on the Internet and mobile with the advent of the big data era. In particular, recommendation systems are widely used to help consumers who struggle to select the best products among such a large amount of information. However, recommendation systems are vulnerable to malicious user biases, such as fake reviews to promote or demote specific products and attacks that steal personal information. Such biases and attacks compromise the fairness of the recommendation model and infringe the privacy of users and systems by distorting data. Recently, deep-learning collaborative filtering recommendation systems have shown to be more vulnerable to this bias. In this position paper, we examine the effects of bias that cause various ethical and social issues and discuss the need for designing a robust recommendation system for fairness and stability.

Gwanghan Lee, Saebyeol Shin, and Simon Woo*
31st ACM International Conference on Information & Knowledge Management (CIKM), Georgia, USA, 2022
BK Computer Science IF=3
Most dynamic pruning methods fail to achieve actual acceleration due to the extra overheads caused by indexing and weight-copying to implement the dynamic sparse patterns for every input sample. To address this issue, we propose Dynamic Pattern-based Pruning Network, which preserves the advantages of both static and dynamic networks. Unlike previous dynamic pruning methods, our novel method dynamically fuses static kernel patterns, enhancing the kernel's representational power without additional overhead. Moreover, our dynamic sparse pattern enables an efficient process using BLAS libraries, accomplishing actual acceleration. We demonstrate the effectiveness of the proposed network on CIFAR and ImageNet, outperforming the state-of-the-art methods achieving better accuracy with lower computational cost.

Binh M. Le, Rajat Tandon, Chingis Oinar, Jeffrey Liu, Uma Durairaj, Jiani Guo, Spencer Zahabizadeh,
Sanjana Ilango, Jeremy Tang, Fred Morstatter, Simon Woo*, and Jelena Mirkovic*
31st ACM International Conference on Information & Knowledge Management (CIKM), Georgia, USA, 2022
BK Computer Science IF=3
In this paper, we propose a fusion model, called Samba, which uses both metadata and video subtitles for content classifying YouTube videos for kids. Previous studies utilized metadata, such as video thumbnails, title, comments, ect., for detecting inappropriate videos for young viewers. Such metadata-based approaches achieve high accuracy but still have significant misclassifications due to the reliability of input features. By adding representation features from subtitles, which are pretrained with a self-supervised contrastive framework, our Samba model can outperform other state-of-the-art classifiers by at least 7%. We also publish a large-scale, comprehensive dataset of 70K videos for future studies.

Shahroz Tariq, Binh M. Le , and Simon Woo*
31st ACM International Conference on Information & Knowledge Management (CIKM), Georgia, USA, 2022
BK Computer Science IF=3
Time series anomaly detection is studied in statistics, ecology, and computer science. Numerous time series anomaly detection strategies have been presented utilizing deep learning. Many of these methods exhibit state-of-the-art performance on benchmark datasets, giving the false impression that they are robust and deployable in a wide variety of real-world scenarios. In this study, we demonstrate that adding modest adversarial perturbations to sensor data severely weakens anomaly detection systems. Under well-known adversarial attacks such as Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD), we demonstrate that the performance of state-of-the-art deep neural networks (DNNs) and graph neural networks (GNNs), which claim to be robust against anomalies and possibly be used in real-world systems, drops to 0%. We demonstrate for the first time, to our knowledge, the vulnerability of anomaly detection systems to adversarial attacks. This study aims to increase awareness of the adversarial vulnerabilities of time series anomaly detectors.

Hanbeen Lee, Jeongho Kim, and Simon Woo*
31st ACM International Conference on Information & Knowledge Management (CIKM), Georgia, USA, 2022
BK Computer Science IF=3
Knowledge distillation (KD) is a powerful technique for improving the performance of a small model by leveraging the knowledge of a larger model. Despite its remarkable performance boost, KD has a drawback with the substantial computational cost of pre-training larger models in advance. Recently, a method called self-knowledge distillation has emerged to improve the model's performance without any supervision. In this paper, we present a novel plug-in approach called Sliding Cross Entropy (SCE) method, which can be combined with existing self-knowledge distillation to significantly improve the performance. Specifically, to minimize the difference between the output of the model and the soft target obtained by self-distillation, we split each softmax representation by a certain window size, and reduce the distance between sliced parts. Through this approach, the model evenly considers all the inter-class relationships of a soft target during optimization. The extensive experiments show that our approach is effective in various tasks, including classification, object detection, and semantic segmentation. We also demonstrate SCE consistently outperforms existing baseline methods.

Youjin Shin, Eun-Ju Park, and Simon Woo*, Okchul Jung and Daewon Chung
31st ACM International Conference on Information & Knowledge Management (CIKM), Georgia, USA, 2022
BK Computer Science IF=3
Although the collision of space objects not only incurs a high cost but also threatens human life, the risk of collision between satellites has increased, as the number of satellites has rapidly grown due to the significant interests in many space applications. However, it is not trivial to monitor the behavior of the satellite in real-time since the communication between the ground station and spacecraft are dynamic and sparse, and there is an increased latency due to the long distance. Accordingly, it is strongly required to predict the orbit of a satellite to prevent unexpected contingencies such as a collision. Therefore, the real-time monitoring and accurate orbit prediction is required. Furthermore, it is necessarily to compress the prediction model, while achieving a high prediction performance in order to be deployable in the real systems. Although several machine learning and deep learning-based prediction approaches have been studied to address such issues, most of them have applied only basic machine learning models for orbit prediction without considering the size, running time, and complexity of the prediction model. In this research, we propose Selective Tensorized multi-layer LSTM (ST-LSTM) for orbit prediction, which not only improves the orbit prediction performance but also compresses the size of the model that can be applied in practical deployable scenarios. To evaluate our model, we use the real orbit dataset collected from the Korea Multi-Purpose Satellites (KOMPSAT-3 and KOMPSAT-3A) of the Korea Aerospace Research Institute (KARI) for 5 years. In addition, we compare our ST-LSTM to other machine learning-based regression models, LSTM, and basic tensorized LSTM models with regard to the prediction performance, model compression rate, and running time.

Younho Jang†, Wheemyung Shin†, Jinbeom Kim, Simon Woo* , and Sung-Ho Bae*
European Conference on Computer Vision (ECCV), Tel Aviv, Oct., 2022
BK Computer Science IF=2 (Acceptance Rate ~ 28%)
Knowledge distillation (KD) is a well-known model compression strategy to improve models' performance with fewer parameters. However, recent KD approaches for object detection have faced two limitations. First, they distill nearby foreground regions, ignoring potentially useful background information. Second, they only consider global contexts, thereby the student model can hardly learn local details from the teacher model. To overcome such challenging issues, we propose a novel knowledge distillation method, GLAMD, distilling both global and local knowledge from the teacher. We divide the feature maps into several patches and apply an attention mechanism for both the entire feature area and each patch to extract the global context as well as local details simultaneously. Our method outperforms the state-of-the-art methods with 40.8 AP on COCO2017 dataset, which is 3.4 AP higher than the student model (ResNet50 based Faster R-CNN) and 0.7 AP higher than the previous global attention-based distillation method.

Gwanghan Lee, Saebyeol Shin, and Simon S. Woo*
한국컴퓨터종합학술대회 (KCC), 2022
조기 종료 네트워크(early-exit network)는 추론 시 동적으로 모델 복잡도를 낮춤으로써 신경망의 효율성을 높인다. 기존 연구들은 입력 샘플이나 모델 구조의 중복성(redundancy)을 줄이는 데 집중하였으나 고차원 특징 정보가 부족한 초기 분류기들이 전체 네트워크 성능에 치명적인 영향을 끼치는 문제를 해결하지 못했다. 본 연구는 중복성을 줄이는 것뿐만 아니라 합성곱 커널(convolution kernel) 중앙에서 가중치들을 공유하면서 효율적으로 다중 스케일(multi-scale) 특징을 생성하여 조기 종료 네트워크의 성능을 향상시킨다. 또한 이 논문의 게이팅 네트워크(gating network)는 네트워크의 서로 다른 위치에 있는 각 합성곱 레이어에 따라 최적의 다중 스케일 특징 비율을 결정하도록 학습된다.
Jeongho Kim, Jeonghyun Kim, Taejune Kim, and Simon S. Woo*
한국컴퓨터종합학술대회 (KCC), 2022, 우수논문상 (Top 7%)
오늘날 국제사회에서 딥페이크(Deepfake) 기술에 대한 우려가 점점 커지고 있다. 딥페이크는 여러 종류의 이미지, 영상들의 얼굴을 짧은 시간 만에 바꿀 수 있는 기술로, 손쉽게 왜곡된 정보를 전파할 수 있기 때문이다. 이에따라딥페이크이미지,영상에대응하기위한탐지기술연구및시도가이뤄졌다. 그러나,탐지기술연구를 가능케 만들어 줄 수 있는 고품질의 데이터셋(dataset)을 생성하는 연구는 더디게 이뤄졌다. 본 논문에서는 딥페 이크 탐지 기술 발전에 필수 불가결한 요소인 고품질 데이터 생성에 대한 새로운 방법론을 제시하고 이를 통해 딥페이크 탐지 기술의 한계 및 발전 방향성에 대해 살펴보고자 한다.
Hajin Kim, Chingis Oinar, UiHyeon Shin, Woo Simon S, and Moon-Young Kim
제29회 대한기초의학 학술대회 (대한법의학회), 2022 우수포스터상
As the number of lonely deaths increases due to the aging population and the increase in single-person households, the frequency of discovery of decomposed corpses in death cases is gradually increasing. In the wake of the strengthening of on-site guidelines by the National Police Agency and the adjustment of the prosecution and police investigation rights, the need for identification and autopsy at the scene is being emphasized. Although the existing forensic face restoration technology using face bones has accumulated a number of previous studies, there is a limitation in that the restoration results may vary due to many factors such as the thickness and nature of facial soft tissue, shape of eyes or nose, and distribution of body hair. Based on the fact that facial recognition technology using facial landmarks is becoming common all over the world, this study aims to help quickly and accurately identify the faces of corrupt bodies that expand due to postmortem-change.
In this study, living data such as ID cards and post-mortem data were collected for bodies identified with fingerprints, and compared pairs were formed, and face recognition technology used the MTCNN model, which is currently widely used in the field. The artificial intelligence model, which determines whether live data and post-data match, selected and analyzed Arcface, which is the same among a total of seven open-source models (VGG-Face, FaceNet, OpenFace, DeepFace, DeepID, ArcFace, Dlib).
The performance of the artificial intelligence model (Arcface) was evaluated by comparing the results of the judgment of the expert group, the general public group, and the entire human group. As a result of comparison using 107 pairs of original data, the same person judgment rate was found to be 51.4% in the expert group, 22.4% in the general population, and 29.0% in the total human group, and the artificial intelligence model was 47.7%. As a result of reviewing the original data, it was determined that changes in skin color due to decomposition could affect the performance of artificial intelligence models According to this judgment, when the original data were preprocessed in gray scale, the judgment rate of the same person as the artificial intelligence model was 50.5%, which showed an improvement in performance of about 3%.
Through this study, it was found that only the currently developed artificial intelligence model showed facial recognition performance close to that of a group of experts. It is expected that face recognition performance can be further improved if various pretreatment technologies reflecting the characteristics of the postmortem change are developed and applied in the future.
인구 고령화 및 1인 가구의 증가는 고독사의 증가로 이어져 변사사건에서 부패 시신이 발견되는 빈도가 점차 높아지고 있다. 경찰청의 현장 지침 강화 및 검경 수사권 조정 등을 계기로 현장에서는 신원 확인 및 부검의 필요성이 강조되고 있다. 얼굴뼈를 활용한 기존의 법의학적 얼굴 복원 기술은 다수의 선행연구 결과가 축적되어 있지만, 얼굴 연부조직의 두께나 성상, 눈이나 코의 형태, 체모의 분포 등의 고려 요소가 많아 복원 결과가 달라질 수 있다는 한계가 존재한다. 본 연구는 얼굴의 특징점(face landmark)을 활용하는 얼굴 인식 기술이 전세계적으로 보편화되고 있다는 점에 착안하여, 사후변화로 인해 연부조직이 팽창된 부패 시신의 얼굴을 복원하거나 생전의 사진과 비교하여 동일인 여부를 판정함으로써 신속하고 정확한 신원확인에 도움을 주고자 한다.
본 연구에서는 지문 등으로 신원이 확인된 시신을 대상으로 신분증 등의 생전 데이터와 검안 또는 부검 당시 촬영된 사후데이터를 수집한 뒤 각각 짝을 지어 비교쌍을 구성하였으며, 얼굴 인식 기술은 현재 해당 분야에서 많이 활용되고 있는 MTCNN 모델을 활용하였다. 생전데이터와 사후데이터의 일치 여부를 판단하는 인공지능모델은 총 7개의 open source 모델(VGG-Face, FaceNet, OpenFace, DeepFace, DeepID, ArcFace, Dlib) 중 가장 동일인 판정률의 빈도가 가장 높게 나타난 Arcface를 선정하여 분석하였다.
인공지능모델(Arcface)의 성능은 전문가집단과 일반인 집단, 전체 사람 집단의 판정 결과와 비교하여 평가하였다. 원본 데이터 107쌍을 이용한 비교 결과, 동일인 판정률은 전문가집단 51.4%, 일반인 22.4%, 전체 사람 집단 29.0%로 조사되었으며, 인공지능모델은 47.7%로 나타났다. 원본 데이터를 검토한 결과, 부패로 인한 피부색의 변화가 인공지능모델의 성능에 영향을 줄 가능성이 있다고 판단되었다. 이러한 판단에 따라 원본 데이터를 회색조(gray scale)로 전처리하였을 때 인공지능모델의 동일인 판정률은 50.5%로, 약 3%의 성능이 향상되는 것을 볼 수 있었다.
본 연구를 통해 현재 개발되어 있는 인공지능모델만으로도 전문가 집단에 근접한 얼굴 인식 성능을 보이는 것을 알 수 있었다. 향후 사후변화의 특성을 반영한 다양한 전처리 기법을 개발하여 적용할 경우 얼굴 인식 성능을 더욱 향상시킬 수 있을 것으로 기대된다.

Siho Han and Simon S. Woo*
ACM SIG KDD, Washington, DC, USA, 2022
BK Computer Science IF=4 (Short Oral Talk)
Anomaly detection in high-dimensional time series is typically tackled using either reconstruction- or forecasting-based deep learning algorithms. Both streams of approach have seen enormous success in terms of detection accuracy due to their abilities to learn compressed data representations and model temporal dependencies, respectively. However, most existing methods disregard the relationships between features, information that would be extremely useful when incorporated into the model. How can we effectively combine the best of reconstruction and forecasting models while also capturing feature interdependencies? In this work, we introduce Fused Sparse Autoencoder and Graph Net (FuSAGNet), which jointly optimizes reconstruction and forecasting while explicitly modeling the relationships within multivariate time series. Our approach combines Sparse Autoencoder and Graph Neural Network, the latter of which predicts future time series behavior from sparse latent representations learned by the former as well as graph structures learned through recurrent feature embedding. Experimenting on three real-world cyber-physical system datasets, we empirically demonstrate that the proposed method enhances the overall anomaly detection performance, outperforming baseline approaches. Moreover, we show that mining sparse latent patterns from high-dimensional time series improves the robustness of the graph-based forecasting model. Lastly, we conduct visual analyses to investigate the interpretability of both recurrent feature embedding vectors and sparse latent representations.

JeongHo Kim†, Taejune Kim†, Jeonghyeon Kim, and Simon S. Woo*
International Conference on Pattern Recognition, Montreal Quebec, 2022
BK Computer Science IF=1
Today, various multimedia content can be accessed and shared from any location via the Internet. In addition to normal content, there is an extensive amount of manipulated multimedia that can raise various social issues and concerns. Among the various types of manipulated media, deepfakes can be abused in impersonation or spreading fake information. Therefore, numerous studies have been performed to detect deepfakes to alleviate these concerns, and studies such as FaceForensics++ (FF++) and DeepFake Detection Challenge (DFDC) have sparked these studies by providing deepfake datasets. The deepfake datasets were utilized for supervised learning in conjunction with developing sophisticated neural networks and showed a high detection performance. Since powerful neural networks can learn even subtle details about an image, they must be trained on realistic deepfakes created by advanced deepfake generation technologies to improve the robustness of existing detectors. In order to boost the performance of deepfake detection models, we propose an approach to creating more realistic deepfake images by removing "detectable" artifacts from existing deepfake datasets' images. By applying the proposed method to the original deepfake dataset, we demonstrate that our technique can significantly reduce the detection performance of existing deepfake detectors. Our experimental results show the vulnerability of deployed detectors and pave the way for further improvement.

Junyaup Kim and Simon S. Woo*
CVPR Workshop on Human-centered Intelligent Services: Safe and Trustworthy, 2022
With the rise of the General Data Protection Regulation (GDPR), user data holders should guarantee the “individual’s right to be forgotten”. It means user data holders must completely remove user data when they receive the request. However, enabling a deep learning model to exclude specific data used during training is challenging. We can’t define what is ”forgetting” in deep learning and how to do it. To address this issue, we propose an efficient machine unlearning architecture to be used for computer vision classification models. Our approach consists of two-stage, where in the first stage we render a deep learning model that loses information with contrastive labels in the requested dataset. Second, we retrain the first stage output model with knowledge distillation (KD). Using this two-stage approach, we can substantiate the removal or forgetness of the requested dataset in the deep learning model. With various datasets used for multimedia applications, we demonstrate that our approach achieves performance on par or even higher accuracy than the original model, while effectively removing the requested data.

Keeyoung Kim and Simon S. Woo*
Workshop on the security implications of Deepfakes and Cheapfakes (WDC), ACM ASIACCS, 2022
Deep Neural Networks (DNNs) are very effective in image classification, detection and recognition due to a large number of available data. However, they can be easily fooled by adversarial examples and produce incorrect results, which can cause problems for many applications. In this work, we focus on generating adversarial images and exploring and assessing possible negative impacts caused by these examples. As a case study, we create adversarial images against Naver’s celebrity recognition (NCR) API, as Naver is the leading machine learning APIs service provider in South Korea. We demonstrate that it is extremely easy to fool the online DNN-based APIs using adversarial examples and discuss possibe negative impacts resulting from these adversarial examples.

Taejune Kim, Jeonghyeon Kim, Jongho Kim, and Simon S. Woo*
Workshop on the security implications of Deepfakes and Cheapfakes (WDC), ACM ASIACCS, 2022
Recently, various image synthesis technologies have increased the prevalence of impersonation attacks, and with the development of such technologies, the amount of damage such as defamation has also increased. Deepfake, the representative of the impersonation technique, has already evolved to the point where people cannot distinguish, leading to an urgent need for detection methods. Currently, in order to detect deepfakes, many deepfake datasets are widely used in deep neural networks using supervision learning. However, although this method is robust to the images synthesized by deepfake generation methods already known, it remains undefined whether deepfakes created by unknown techniques can be detected. Accordingly, to detect more challenging deepfakes, we present a pre-processing technique that mitigates the artifacts of deepfakes and makes them appear more natural. The proposed method can be combined with the existing deepfake creation method to generate a more threatening deepfake image. Furthermore, through extensive experiments, we demonstrate that our method can significantly lower the performance of state-of-the-art detectors and expose the vulnerability of deployed detectors.

Donggeun Ko, Sangjun Lee, Jinyong Park, Saebyeol Shin, Donghee Hong, and Simon S. Woo*
Workshop on the security implications of Deepfakes and Cheapfakes (WDC), ACM ASIACCS, 2022
Hyper-realistic face image generation and manipulation have givenrise to numerous unethical social issues, e.g., invasion of privacy,threat of security, and malicious political maneuvering, which re-sulted in the development of recent deepfake detection methodswith the rising demands of deepfake forensics. Proposed deepfakedetection methods to date have shown remarkable detection perfor-mance and robustness. However, none of the suggested deepfakedetection methods assessed the performance of deepfakes withthe facemask during the pandemic crisis after the outbreak of theCovid-19. In this paper, we thoroughly evaluate the performance ofstate-of-the-art deepfake detection models on the deepfakes withthe facemask. Also, we propose two approaches to enhance themasked deepfakes detection:face-patchandface-crop. The experi-mental evaluations on both methods are assessed through the base-line deepfake detection models on the various deepfake datasets.Our extensive experiments show that, among the two methods,face-cropperforms better than theface-patch, and could be a trainmethod for deepfake detection models to detect fake faces withfacemask in real world.
Geonwoo Park, Eunju Park, and Simon S. Woo*
Workshop on the security implications of Deepfakes and Cheapfakes (WDC), ACM ASIACCS, 2022
With the growth of deep learning studies, the technologies of generating deepfake videos have been advanced. While the manipulated videos are so sophisticated that one cannot differentiate between real and fake, one can create such videos with little effort. These technologies are likely to be abused by people with malicious intent. To address the problem, the algorithms for detecting deepfakes have been researched abundantly. The performance of the detectors, however, depends on the amount and the domain of the training data. In this paper, we introduce a new deepfake dataset generated by an algorithm changing an original image to a sequence of fake images. We evaluate existing models detecting deepfakes on the new dataset and demonstrate that the accuracy of the models degrades. Their performance is recovered when trained with the new dataset.

Youjin Shin and Simon S. Woo*
Elsevier Computers & Security, Jan 2022
SCIE Q1 IF=4.4
A textual password is widely used for user authentication for a variety of applications. Passwords that are easy to remember are also easy to be guessed, while complex and long passwords that provide strong security are difficult to remember. Also, there has been limited quantitative research to understand the factors that make passwords strong. In this research, we aim to expand our understanding of passwords through the lenses of data-driven analysis by characterizing a large number of password datasets with four different hypotheses. In particular, we use the tensor decomposition method that is effective in analyzing unlabeled high dimensional data. We first obtain 362,805 passwords from four different leaked password datasets. Next, we generate syntactic and semantic features for each password, then classify it into three strength groups using a statistical guessing attack model. Finally, we construct a 3rd-order password tensor and decompose it using the PARAFAC2 algorithm to examine the main characteristics which make passwords strong.

JunHyung Kang, Shahroz Tariq, Han Oh, and Simon S. Woo*
IEEE Access
SCIE
Although extensive studies in deep learning-based object detection have achieved remarkable performance and success, they are still ineffective yielding a low detection performance, due to the underlying difficulties in overhead images. Thus, high-performing object detection in overhead images is an active research field to overcome such difficulties. This survey paper provides a comprehensive overview and comparative reviews on the most up-to-date deep learning-based object detection in overhead images. Especially, our work can shed light on capturing the most recent advancements of object detection methods in overhead images and the introduction of overhead datasets that have not been comprehensively surveyed before.

Shahroz Tariq, Sowon Jeon, and Simon S. Woo*
The 31st Web Conference (WWW), France, April 2022
BK Computer Science IF=4
Recent advancements in web-based multimedia technologies, such as face recognition web services powered by deep learning, have been significant. However, such technologies face persistent threats, as virtually anyone with access to deepfakes can quickly launch impersonation attacks, which pose a serious threat to authentication services. Despite its gravity, deepfake abuse involving commercial web services have not been investigated. Thus, we examine the robustness of black-box commercial face recognition web APIs (Microsoft, Amazon, Naver, and Face++) and open-source tools (VGGFace and ArcFace) against Deepfake Impersonation (DI) attacks. We demonstrate the vulnerability of face recognition technologies to DI attacks, achieving respective success rates of 78.0% for targeted (TA) attacks; we also propose mitigation strategies, lowering respective attack success rates to as low as 1.26% for TA attacks with adversarial training.

Sangyup Lee, Jaeju An, and Simon S. Woo*
The 31st Web Conference (WWW), France, April 2022
BK Computer Science IF=4
Generating a deep learning-based fake video has become no longer rocket science. The advancement of automated Deepfake (DF) generation tools that mimic certain targets has rendered society vulnerable to fake news or misinformation propagation. In real-world scenarios, DF videos are compressed to low-quality (LQ) videos, taking up less storage space and facilitating dissemination through the web and social media. Such LQ DF videos are much more challenging to detect than high-quality (HQ) DF videos. To address this challenge, we rethink the design of standard deep learning-based DF detectors, specifically exploiting feature extraction to enhance the features of LQ images. We propose a novel LQ DF detection architecture, multi-scale Branch Zooming Network (BZNet), which adopts an unsupervised super-resolution (SR) technique and utilizes multi-scale images for training. We train our BZNet only using highly compressed LQ images and experiment under a realistic setting, where HQ training data are not readily accessible. Extensive experiments on the FaceForensics++ LQ and GAN-generated datasets demonstrate that our BZNet architecture improves the detection accuracy of existing CNN-based classifiers by 4.21\% on average. Furthermore, we evaluate our method against a real-world Deepfake-in-the-Wild dataset collected from the internet, which contains 200 videos featuring 50 celebrities worldwide, outperforming the state-of-the-art methods by 4.13%.

Jeong-Han Yun, Jonguk Kim, Won-Seok Hwang, Young Geun Kim, Simon S. Woo and Byung-Gil Min
ACM-SAC, Virtual, 2022
BK Computer Science IF=1
Unsupervised anomaly detection is commonly performed by identifying unusual data samples (or anomalies) from the residual size produced by machine learning algorithms based on normal data (e.g., the residuals of regression models or reconstruction errors of autoencoder models), assuming that anomalies cause large residuals. Unfortunately, anomalies do not always cause large residuals. Anomaly detection algorithms based on residual size can miss anomalies that cause only small or noisy residuals for each variable in a multivariate time-series. To overcome this issue, we propose "neighbors to residuals" (N2RE), a novel anomaly scoring function based on residual similarity using nearest neighbor distance (NND). Even if residuals of anomalies are small, they show patterns that are different from those of residuals of normal data. Using N2RE can improve anomaly detection performance and reduce the variation in anomaly detection performance due to threshold changes. Experiments with various models on three cyber-physical system datasets verify that N2RE can achieve 19% higher anomaly detection performance than previous approaches without changes to the models.
Jeongho Kim, Shahroz Tariq, and Simon S. Woo*
ACM-SAC, Virtual, 2022
BK Computer Science IF=1
Training data may include personal information such as human faces, which requires anonymization to provide user privacy. However, after anonymization, the performance of the original machine learning (ML) model degrades due to the reduced or missing information. In this work, we introduce a novel privacy-preserving tensor decomposition (PTD) method to anonymize human faces. Further, we evaluate real vs. fake human face detection task as a practical use case scenario. Our approach achieves high performance as well as training data efficiency, where the essence of our approach is based on tensor decomposition to ensure face data privacy. In particular, we demonstrate that the core tensor of Tucker decomposition generated from the original face input can effectively represent the underlying characteristics of the original face data; that is, learning only from the core tensors is sufficient for differentiating real human face images from deepfakes. Also, we show that the original human face inputs are anonymized and cannot be recovered from the core tensors under different attacker models from the randomized HOOI algorithm. Through extensive experiments and analysis, we demonstrate that our method can result in high detection performance comparable to those of popular anonymization methods. Therefore, we show that our work strikes the balance between privacy and performance through the novel use of tensor decomposition.

Binh M. Le and Simon S. Woo*
Thirty-Sixth AAAI Conference on Artificial Intelligence, Canada, 2022
BK Computer Science IF=4 (Acceptance Rate ~ 15%)
Despite significant advancements of deep learning-based forgery detectors for distinguishing manipulated deepfake images, most detection approaches suffer from moderate to significant performance degradation with low-quality compressed deepfake images. Because of the limited information in low-quality images, detecting low-quality deepfake remains an important challenge. In this work, we apply frequency domain learning and optimal transport theory in knowledge distillation (KD) to specifically improve the detection of low-quality compressed deepfake images. We explore transfer learning capability in KD to enable a student network to learn discriminative features from low-quality images effectively. In particular, we propose the Attention-based Deepfake detection Distiller (ADD), which consists of two novel distillations: 1) frequency attention distillation that effectively retrieves the removed high-frequency components in the student network, and 2) multi-view attention distillation that creates multiple attention vectors by slicing the teacher’s and student’s tensors under different views to transfer the teacher tensor’s distribution to the student more efficiently. Our extensive experimental results demonstrate that our approach outperforms state-of-the-art baselines in detecting low-quality compressed deepfake images.

Hasam Khalid, Shahroz Tariq, TaeSoo Kim, Jong Hwan Ko, and Simon S. Woo*
Neural Processing Letters (SCIE IF=2.9)
Detecting human speech is foundational for a wide range of emerging intelligent applications. However, accurately detecting human speech is challenging, especially in the presence of unknown noise patterns. Generally, deep learning-based methods have shown to be more robust and accurate than statistical methods and other existing approaches. However, typically creating a noise-robust and more generalized deep learning-based Voice Activity Detection (VAD) system requires the collection of an enormous amount of annotated audio data. In this work, we develop a generalized model trained on limited types of human speeches with noisy backgrounds. Yet, it can detect human speech in the presence of various unseen noise types, which were not present in the training set. To achieve this, we propose a One-Class Residual connections-based Variational Autoencoder (ORVAE), which only requires a limited number of human speech data with noisy background for training, thereby eliminating the need for collecting data with diverse noise patterns. Evaluating ORVAE with three different datasets (synthesized TIMIT and NOI SEX-92, synthesized LibriSpeech and NOISEX-92, and a Publicly Recorded dataset), our method outperforms other one-class baseline methods, achieving 1-scores of over 90% for multiple Signal-to-Noise Ratio (SNR) levels.

2021
Hasam Khalid, Minha Kim, Shahroz Tariq, and Simon S. Woo*
Proceedings of the 1st Workshop on Synthetic Multimedia - Audiovisual Deepfake Generation and Detection
Significant advancements made in the generation of deepfakes have caused security and privacy issues. Attackers can easily impersonate a person's identity in an image by replacing his face with the target person's face. Moreover, a new domain of cloning human voices using deep-learning technologies is also emerging. Now, an attacker can generate realistic cloned voices of humans using only a few seconds of audio of the target person. With the emerging threat of potential harm deepfakes can cause, researchers have proposed deepfake detection methods. However, they only focus on detecting a single modality, i.e., either video or audio. On the other hand, to develop a good deepfake detector that can cope with the recent advancements in deepfake generation, we need to have a detector that can detect deepfakes of multiple modalities, i.e., videos and audios. To build such a detector, we need a dataset that contains video and respective audio deepfakes. We were able to find a most recent deepfake dataset, Audio-Video Multimodal Deepfake Detection Dataset (FakeAVCeleb), that contains not only deepfake videos but synthesized fake audios as well. We used this multimodal deepfake dataset and performed detailed baseline experiments using state-of-the-art unimodal, ensemble-based, and multimodal detection methods to evaluate it. We conclude through detailed experimentation that unimodals, addressing only a single modality, video or audio, do not perform well compared to ensemble-based methods. Whereas purely multimodal-based baselines provide the worst performance.

Hasam Khalid, Shahroz Tariq, Minha Kim, and Simon S. Woo*
Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track
While the significant advancements have made in the generation of deepfakes using deep learning technologies, its misuse is a well-known issue now. Deepfakes can cause severe security and privacy issues as they can be used to impersonate a person's identity in a video by replacing his/her face with another person's face. Recently, a new problem of generating synthesized human voice of a person is emerging, where AI-based deep learning models can synthesize any person's voice requiring just a few seconds of audio. With the emerging threat of impersonation attacks using deepfake audios and videos, a new generation of deepfake detectors is needed to focus on both video and audio collectively. A large amount of good quality dataset is typically required to capture the real-world scenarios to develop a competent deepfake detector. Existing deepfake datasets either contain deepfake videos or audios, which are racially biased as well. Hence, there is a crucial need for creating a good video as well as audio deepfake dataset, which can be used to detect audio and video deepfake simultaneously. To fill this gap, we propose a novel Audio-Video Deepfake dataset (FakeAVCeleb) that contains not only deepfake videos but also respective synthesized lip-synced fake audios. We generate this dataset using the current most popular deepfake generation methods. We selected real YouTube videos of celebrities with four racial backgrounds (Caucasian, Black, East Asian, and South Asian) to develop a more realistic multimodal dataset that addresses racial bias, and further help develop multimodal deepfake detectors. We performed several experiments using state-of-the-art detection methods to evaluate our deepfake dataset and demonstrate the challenges and usefulness of our multimodal Audio-Video deepfake dataset.

Jaeeju An, Jeongho Kim, Hanbeen Lee, Jinbeoom Kim, Junhyung Kang, Minha Kim, Saebyeol Shin, Minha Kim, Donghe Hong and Simon S. Woo*
Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track
Detection of fallen persons due to, for example, health problems, violence, or accidents, is a critical challenge. Accordingly, detection of these anomalous events is of paramount importance for a number of applications, including but not limited to CCTV surveillance, security, and health care. Given that many detection systems rely on a comprehensive dataset comprising fallen person images collected under diverse environments and in various situations is crucial. However, existing datasets are limited to only specific environmental conditions and lack diversity. To address the above challenges and help researchers develop more robust detection systems, we create a novel, large-scale dataset for the detection of fallen persons composed of fallen person images collected in various real-world scenarios, with the support of the South Korean government. Our Vision-based Fallen Person (VFP290K) dataset consists of 294,714 frames of fallen persons extracted from 178 videos, including 131 scenes in 49 locations. We empirically demonstrate the effectiveness of the features through extensive experiments analyzing the performance shift based on object detection models. In addition, we evaluate our VFP290K dataset with properly divided versions of our dataset by measuring the performance of fallen person detecting systems. We ranked first in the first round of the anomalous behavior recognition track of AI Grand Challenge 2020, South Korea, using our VFP290K dataset, which can be found here. Our achievement implies the usefulness of our dataset for research on fallen person detection, which can further extend to other applications, such as intelligent CCTV or monitoring systems. The data and more up-to-date information have been provided at our VFP290K site.

Kihyung Joo and Simon S. Woo*
20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, Dec, 2021
Current state-of-the-art autonomous driving technology significantly advanced, leveraging reinforcement learning (RL) algorithms, because it is not easy to apply a rule-based driving method that reflects all the various traffic conditions. Indeed, reinforcement learning can produce the possible optimal driving strategy of urban, rural, and motorway roads in various environmental conditions such as speed limits and school zones. However, it is challenging to adjust the parameters of the reward mechanism in RL, because the driving style of each user is very different. And it takes a massive amount of time and resources to conduct RL by reflecting all complex traffic conditions. However, if RL imitates the driving behavior of an expert, RL algorithm can proceed more quickly. Therefore, we propose a novel imitation learning framework, which combines an expert's driving behavior with a continuous behavior of an agent. Further, a deep reinforcement learning approach is used to mimic the expert's driving behavior. Therefore, we propose imitation learning with variational inference and distributional reinforcement learning (IVDR) algorithm. Our results show that IVDR achieves 80% better learning speed than the learning speed of other approaches and outperforms 12% higher in average reward. Our work shows great promise of using RL for autonomous driving and real vehicle driving simulation.

Gwanghan Lee, Minha Kim, Minha Kim, and Simon S. Woo*
30th ACM International Conference on Information and Knowledge Management
BK Computer Science IF=3
Recently, an early exit network, which dynamically adjusts the model complexity during inference time, has achieved remarkable performance. However, they were unsuccessful at resolving the performance drop of early classifiers that make predictions with insufficient high-level feature information. Consequently, the performance degradation of early classifiers had a devastating effect on the entire network performance sharing the backbone. In this paper, we propose an Efficient Multi-Scale Feature Generation Adaptive Network (EMGNet), which not only reduced the redundancy of the architecture but also generates multi-scale features to improve the performance of the early exit network.

Sunny Yun and Simon S. Woo*
Korean Journal of Aerospace and Environmental Medicine(KJAsEM), August 2021
In the era of the 4th industrial revolution, the aviation industry is also growing remarkably with the development of artificial intelligence and networks, so it is necessary to study a new concept of CRM, which is required in the process of operating state-of-the-art equipment. The automation system, which has been treated only as a tool, is changing its role as a decision-making agent with the development of AI, and it is necessary to set clear standards for the role and responsibility in the safety-critical field. We present a new perspective on the automation system in the CRM program through the understanding of the autonomous system. In the future, autonomous system will develop as an agent for human pilots to cooperate, and accordingly, changes in role division and reorganization of regulations are required.
JunHyung Kang and Simon S. Woo*
4th International Conference on Artificial Intelligence and Pattern Recognition, 2021
We propose DLPNet, a novel RL module to enable robust and stable training while achieving high performance in practical small mini-batch size conditions. DLPNet observes input image patches and acts to select the optimal parameters of the dynamic focal loss function for the baseline detector with every mini-batch training iteration during the training phase.

Minha Kim, Shahroz Tariq and Simon S. Woo*
The 29th ACM International Conference on Multimedia (ACMMM '21), Chengdu, China, Oct 20-24, 2021
BK Computer Science IF=4 (Oral Talk)
In this work, we apply continuous learning to neural networks' learning dynamics, emphasizing its potential to increase data efficiency significantly. We propose Continual Representation using Distillation (CoReD) method that employs the concept of Continual Learning (CoL), Representation Learning (ReL), and Knowledge Distillation (KD). We design CoReD to perform sequential domain adaptation tasks on new deepfake and GAN-generated synthetic face datasets, while effectively minimizing the catastrophic forgetting in a teacher-student model setting. Our extensive experimental results demonstrate that our method is efficient at domain adaptation to detect low-quality deepfakes videos and GAN-generated images from several datasets, outperforming the-state-of-art baseline methods.

Sowon Jeon, Gilhee Lee, Hyoungshick Kim and Simon S. Woo*
2021 KDD Workshop on Programming Language Processing (PLP 2021) The Best Paper Award
In this paper, we propose SmartConDetect to detect security vulnerabilities in smart contracts written in Solidity, which the most popular programming language for writing smart contracts on the Ethereum platform. SmartConDetect is designed as a static analysis tool to extract code fragments from smart contracts in Solidity and analyze code patterns using a pre-trained BERT model and a bidirectional LSTM model.

Le Minh Binh and Simon S. Woo*
International Workshop on Safety and Security of Deep Learning, IJCAI 2021
In this paper, we propose a new approach that explores the asynchronous frequency spectra of color channels, which is simple but effective for training both unsupervised and supervised learning models to distinguish GAN-based synthetic images.

Minha Kim, Shahroz Tariq, Simon S. Woo*
WORKSHOP ON MEDIA FORENSICS, CVPR 2021
As GAN-based video and image manipulation technologies become more sophisticated and easily accessible, there is an urgent need for effective deepfake detection technologies. Moreover, various deepfake generation techniques have emerged over the past few years.

William Aiken, Hyoungshick Kim, Simon S. Woo* , and Jungwoo Ryoo
Elsevier Computers & Security, accepted on April 2021
SCIE Q1 IF=3.58
Creating a state-of-the-art deep-learning system requires vast amounts of data, expertise, and hardware, yet research into embedding copyright protection for neural networks has been limited. One of the main methods for achieving such protection involves relying on the susceptibility of neural networks to backdoor attacks, but the robustness of these tactics has been primarily evaluated against pruning, fine-tuning, and model inversion attacks.

Oh, Junhyoung and Hong, Jinhyoung and Lee, Changsoo and Lee, Jemin Justin and Simon S. Woo* and Lee, Kyungho
IEEE Access
SCIE Q1 IF=3.67
In this study, we analyze GDPR provisions and recitals as well as relevant EU guidelines to propose quantifiable consent conditions to check whether website providers are compliant with the GDPR. We then evaluate the extent to which various popular web service providers meet these conditions.

Shahroz Tariq, Sowon Jeon, and Simon S. Woo*
arXiv
This work provides a measurement study on the robustness of black-box commercial face recognition APIs against Deepfake Impersonation (DI) attacks using celebrity recognition APIs as an example case study We achieved maximum success rates of 78.0% and 99.9% for targeted (ie, precise match) and non-targeted (ie, match with any celebrity) attacks, respectively. Moreover, we propose practical defense strategies to mitigate DI attacks, reducing the attack success rates to as low as 0% and 0.02% for targeted and non-targeted attacks, respectively.
News-1
News-2
News-3
News-4
News-5
News-6
News-7
News-8
News-9
News-10
News-11

Young Geun Kim, Jeong-Han Yun, Siho Han, Hyoung Chun Kim, and Simon S. Woo*
36th International Conference on ICT Systems Security and Privacy Protection – IFIP SEC 2021, 22–24 June 2021
BK Computer Science IF=1
In this work, we focus on improving the anomaly detection performance by leveraging the forecasting error patterns generated from prediction models, such as Sequence-to-Sequence (seq2seq), Mixture Density Networks (MDNs), and Recurrent Neural Networks (RNNs). To this end, we introduce Self-Organizing Map-based Anomaly Detector (SOMAD), an anomaly detection framework based on a novel test statistic, SomAnomaly, for Cyber-Physical System (CPS) security.

Sangyup Lee, Shahroz Tariq, Junyaup Kim, and Simon S. Woo*
36th International Conference on ICT Systems Security and Privacy Protection – IFIP SEC 2021, 22–24 June 2021
BK Computer Science IF=1
This work introduces a practical digital forensic tool to detect different types of deepfakes simultaneously and proposes Transfer learning-based Autoencoder with Residuals (TAR). The ultimate goal of this work is to develop an uni fied model to detect various types of deepfake videos with high accuracy, with only a small number of training samples that can work well in real-world settings. To achieve this, this work develops an autoencoder-based detection model with Residual blocks and sequentially performs transfer learning to detect different types of deepfakes simultaneously. The detection model shows a high detection performance not only on the FF++ dataset but also on 200 real-world Deepfake-in-the-wild videos.

Sangyup Lee, Shahroz Tariq, Youjin Shin, and Simon S. Woo*
Elsevier Applied Soft Computing, accepted on Feb 2021
SCIE Q1 IF=5.47
In this work, we introduce a novel Handcrafted Facial Manipulation (HFM) image dataset and soft computing neural network models (Shallow-FakeFaceNets) with an efficient facial manipulation detection pipeline. Our neural network classifier model, Shallow-FakeFaceNet (SFFN), shows the ability to focus on the manipulated facial landmarks to detect fake images. This study is targeted for developing an automated defense mechanism to combat fake images used in different online services and applications, leveraging our state-of-the-art handcrafted fake facial dataset (HFM) and the neural network classifier Shallow-FakeFaceNet (SFFN).

Jaeju An, Jeongho Kim, Bosung Yang, Geonwoo Park, Simon S. Woo
Third Workshop on Fairness, Accountability, Transparency, Ethics and Society on the Web (FATES) Joint with The Web Conference 2021, Ljubljana, Slovenia,
Recent advancements in deep learning have allowed, among others,various applications of face recognition systems, where a largeamount of face image data are typically required for training.


Shahroz Tariq, Sangyup Lee, and Simon S. Woo
The 30th Web Conference (WWW), Ljubljana, Slovenia, April 19, 2021
BK Computer Science IF=4, Acceptace rate = 20.6%
Beyond detecting a single type of DF from benchmark deepfake datasets, we focus on developing a generalized approach to detect multiple types of DFs, including deepfakes from unknown generation methods such as DeepFake-in-the-Wild (DFW) videos. To better cope with unknown and unseen deepfakes, we introduce a Convolutional LSTM-based Residual Network (CLRNet), which adopts a unique model training strategy and explores spatial as well as the temporal information in a deepfakes. Through extensive experiments, we show that existing defense methods are not ready for real-world deployment. Whereas our defense method (CLRNet) achieves far better generalization when detecting various benchmark deepfake methods (97.57% on average). Furthermore, we evaluate our approach with a high-quality DeepFake-in-the-Wild dataset, collected from the Internet containing numerous videos and having more than 150,000 frames. Our CLRNet model demonstrated that it generalizes well against high-quality DFW videos by achieving 93.86% detection accuracy, outperforming existing state-of-the-art defense methods by a considerable margin.

Bong Gon Kim, Young-Seob Cho, Seok-hyun Kim, Hyoungshick Kim, and Simon S. Woo
IEEE Access, Jan 2021
SCIE Q1 IF=4.09
Decentralized identifiers (DID) has shown great potential for sharing user identities across different domains and services without compromising user privacy. DID is designed to enable the minimum disclosure of the proof from a user’s credentials on a need-to-know basis with a contextualized delegation.

Sujin Park, Sangwon Lee, and Simon S. Woo
SAC: The 36th ACM/SIGAPP Symposium On Applied Computing, Gwangju, Korea, 2021.
BK Computer Science IF=1
In this work, we propose BertLoc, a novel deep learning-based architecture to detect the duplicate location represented in different ways (e.g., Cafe vs. Coffee House) and effectively merge them into a single and consistent location record. BertLoc is based on Multilingual Bert Model followed by BiLSTM and CNN to effectively compare and determine whether given location strings are the same location or not. We evaluate BertLoc trained with more than half a million location data used in real service in South Korea and compare the results with other popular baseline methods. Our experimental results show that BertLoc outperforms other popular baseline methods with 0.952 F1-score, and shows great promise in detecting duplicate records in a large-scale location dataset.

2020
Junyaup Kim, Siho Han and Simon S. Woo
Cyber Defence Next Generation Technology and Science Conference.(2020), March 2020
In this research, we present a performance evaluation of existing image hashing algorithms on defending deep learning models against adversarial attacks as an initial work to developing a new, time efficient image hashing algorithm. Upon experimenting with existing image hashing algorithms, we conclude that the wavelet hashing algorithm achieves the highest accuracy (75%) when detecting images generated from Neural Networks attacked by the FGSM, with a time complexity of 𝑂(𝑁).

Minha Kim, Hakjun Moon and Simon S. Woo
CISC-W, 2020
Currently used cryptography algorithms like RSA are vulnerable to quantum computers and are at risk of being deciphered in polynomial time. As the commercialization of quantum computers is soon to be realized, there is an urgent need for developing post-quantum cryptography(PQC) algorithms. In this paper, we analyze several lattice-based PQC algorithms from NIST Post-Quantum Cryptography Standardization project and test them in some representative security protocols to show their practicality.

Hyeonseong Jeon, Siho Han, Sangwon Lee and Simon S. Woo
15th Asian Conference on Computer Vision (ACCV), Kyoto, Japan, 2020
BK Computer Science IF=1
We introduce a novel framework, Extra Representation (ExRep), to surmount the problem of not having access to the JFT-300M data by instead using ImageNet and the publicly available model that has been pre-trained on JFT-300M. We take a knowledge distillation approach, treating the model pre-trained on JFT-300M as well as on ImageNet as the teacher network and that pre-trained only on ImageNet as the student network. Our proposed method is capable of learning additional representation effects of the teacher model, bolstering the student model’s performance to a similar level to that of the teacher model, achieving high classification performance even without extra training data.

Youjin Shin, Shahroz Tariq, Sangyup Lee, Myeong Shin Lee, Okchul Jung, Daewon Chung, and Simon S. Woo
CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Galway, Ireland
BK Computer Science IF=3
Reducing false positives while detecting anomalies is of growing importance for various industrial applications and mission-critical infrastructures, including satellite systems. Undesired false positives can be costly for such systems, bringing the operation to a halt for human experts to determine if the anomalies are true anomalies that need to be mitigated

Sangyup Lee, Simon S. Woo, Jinhwan Kim, Okyeop Jeon
Proceedings of the Korean Information Science Society Conference 2020 (한국법과학회 2020 추계학술대회)
Deepfakes have become a critical social problem, and detecting them is of utmost importance. Detecting high-quality deepfake videos from widely released datasets is more straightforward to detect than low-quality ones. Most of the prior research achieve above 90% accuracy for detecting the high-quality deepfake videos from the open dataset. However, in real life, many deepfake videos that are leaked through social networks such as YouTube and instant messaging applications are highly compressed. As a result, the distributed video's resolution becomes extremely lower, making the state-of-the-art detection methods harder. In this work, we propose ZoomNet, a practical framework to detect low-quality deepfakes with high accuracy. We build ZoomNet to have the ability to zoom into low-quality images effectively and can learn to distinguish deepfakes from real videos.

DaeYoung Yoon and Simon S. Woo
CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Galway, Ireland
BK Computer Science IF=3
The recent paramount success of the gig economy has introduced new business opportunities in different areas such as food delivery service. However, there are food delivery ride abusers who break the company rule by driving unauthorized vehicles that are not stated in the contract

Eunsoo Kim, Young-Seob Cho, Bedeuro Kim, Woojoong Ji, Seok-hyun Kim and Simon S. Woo
IEEE Internet of Things Magazine, 2020
Providing a cross-domain federated identity is essential for next-generation Internet services because information about user identity should be seamlessly exchanged across different domains for authentication and authorization.

Keeyoung Kim, Jinseok Hong, Sang-Hoon Rhee and Simon S. Woo
ECML-PKDD, Ghent, Belgium 2020
Acceptance Rate=28%
Hasam Khalid and Simon S. Woo
IEEE Biometrics Council newsletter
An image forgery method called Deepfakes can cause security and privacy issues by changing the identity of a person in a photo through the replacement of his/her face with a computer-generated image or another person’s face.

Seoyoung Park*, Siho Han* and Simon S. Woo
ECML-PKDD, Ghent, Belgium 2020
Acceptance Rate=28%
We propose novel Functional Data Analysis (FDA) and Autoencoder-based approaches for anomaly detection in the Secure Water Treatment (SWaT) dataset, which realistically represents a scaled-down industrial water treatment plant. We demonstrate that our methods can capture the underlying forecasting error patterns of the SWaT dataset generated by Mixture Density Networks (MDNs).

Sowon Jeon, Junhyung Kang, Jinhee Hwang and Simon S. Woo
CISC-S, 2020
우수논문상
최근 한국에서 ‘가짜 연예인 음란 동영상’ 및 ‘지인 능욕’에 사용되는 딥페이크(Deepfakes) 포르노 문제가 사회적인 이슈로 불거지고 있다. 딥페이크 기술은 인공지능 기술의 발전에 맞추어 더욱더 빠르게 발전하고 있으나 관련 규제와 대응방안이 부족한 실정이다. 따라서 본 논문에서는 딥페이크 기술의 현황과 딥페이크 관련 국내외 법적 규제 및 현행법의 한계점을 살펴보고, 이로부터 각 개인 및 기관의 역할과 대응방안을 제안한다.

Hyeonseong Jeon, Youngoh Bang, Junyaup Kim, and Simon S. Woo
Thirty-seventh International Conference on Machine Learning (ICML), Vienna, Austria, 2020
BK Computer Science IF=4, Acceptance Rate=18.48%
In this work, we present the Transferable GAN-images Detection framework (T-GD), a robust transferable framework for an effective detection of GAN-images. T-GD is composed of a teacher and a student model that can iteratively teach and evaluate each other to improve the detection performance.

Dan Zhang, and Simon S. Woo
IEEE Access, May 2020
SCIE Q1 IF=4.09
Air pollution and its harm to human health has become a serious problem in many cities around the world. In recent years, research interests in measuring and predicting the quality of air around people has spiked.
Shahroz Tariq, Sangyup Lee, Huy Kang Kim, and Simon S. Woo
Elsevier Computers & Security, December 2020
SCIE Q1 IF=3.58
In recent years, there has been significant interest in developing autonomous vehicles such as self-driving cars. In-vehicle communications, due to simplicity and reliability, a Controller Area Network (CAN) bus is widely used as the de facto standard to provide serial communications between Electronic Control Units (ECUs)

Hasam Khalid and Simon S. Woo
Workshop on Media Forensics, CVPR 2020, Monday, 15th June 2020, Seattle, USA
An image forgery method called Deepfakes can cause security and privacy issues by changing the identity of a person in a photo through the replacement of his/her face with a computer-generated image or another person’s face.
Hanbin Jang, Woojung Ji, and Simon S. Woo
The 25th Australasian Conference on Information Security and Privacy, Perth, Australia, 2020
Acceptance rate ~ = 20%
Most shipping companies provide a package tracking system where customers can easily track their package delivery status when the package is being shipped. However, we present a security problem called enumeration attacks against package tracking systems...
Simon S. Woo
The 29th Web Conference (WWW), Taipei, Taiwan, 2020
BK Computer Science IF=4, Acceptance Rate=19%
Although pronounceability can improve password memorability, most existing password generation approaches have not properly integrated the pronounceability of passwords in their designs. In this work, we demonstrate several shortfalls of current pronounceable password generation approaches, and then propose, ProSemPass, a new method of generating passwords that are pronounceable and semantically meaningful.
Simon S. Woo,Hanbin Jang, Woojung Ji and Hyoungshick Kim
The 29th Web Conference (WWW), Taipei, Taiwan, 2020
BK Computer Science IF=3, Acceptance Rate=19%
A package tracking number (PTN) is widely used to monitor and track a shipment. Through the lenses of security and privacy, however, a package tracking number can possibly reveal certain personal information, leading to security and privacy breaches.
Hyeonseong Jeon, Youngoh Bang, and Simon S. Woo
SEC 2020 International Conference on Information Security and Privacy Protection (IFIP-SEC), Solvenia, Sept 2020
BK Computer Science IF=1
Creating fake images and videos such as "Deepfake" has become much easier these days due to the advancement in Generative Adversarial Networks (GANs). Moreover, recent research such as the few-shot learning can create highly realistic personalized fake images with only a few images.
Joon Kuy Han, Xiaojun Bi, Hyoungshick Kim, and Simon S. Woo
ASIACCS: The 13th ACM Asia Conference on Computer and Communications Security, Taipei, Taiwan, 2020.
BK Computer Science IF=1
Designing a fallback authentication mechanism that is both memorable and strong is a challenging problem because of the trade-off between usability and security. Security questions are popularly used as a fallback authentication method for password recovery.
Jihye Woo, Ji Won Choi, Soyoon Jeon, Joon Han, Hyoungshick Kim, and Simon S. Woo
AsiaUSEC, Feb. 2020
Internet users in South Korea seem to have clearly different web browser choices and usage patterns compared to the rest of the world, heavily using Internet Explorer (IE) or multiple browsers.
Shahroz Tariq, Sangyup Lee, and Simon S. Woo
The 35th ACM/SIGAPP Symposium On Applied Computing (SAC), Brno, Czech Republic, March 2020
BK Computer Science IF=1
In-vehicle communications, due to simplicity and reliability, a Controller Area Network (CAN) bus is widely used as the de facto standard to provide serial communications between Electronic Control Units (ECUs).
2019
Jelena Mirkovic and Simon S. Woo
2019 IEEE Humans and Cyber Security (HACS) workshop in conjunction with IEEE CogMI (Cognitive Machine Intelligence), IEEE CIC (Collaboration and Internet Computing) and IEEE TPS (Trust, Privacy and Security of Intelligence Systems, and Applications) Los Angeles, California, USA, December 14, 2019.
Security and privacy solutions today are designed with an assumption of a rational user. System designers assume that the user is able to review all information shown to them, consider it along with other information they have, and user priorities, and make a conscious, rational decision in their best interest.
Junyaup Kim, Siho Han, and Simon S. Woo
2019 IEEE International conference on Big Data (IEEE BigData 2019), Los Angeles, CA, USA
In this preliminary work, we aim to detect a target person's face from different similar individuals, Doppelgangers, leveraging the dataset from Disguised Faces in the Wild (DFW) 2018. We use well-known off-the-shelf face detection classifiers, such as ShallowNet, VGG-16, and Xception to evaluate the classification performance. In order to further improve the detection performance, we apply data augmentation. Our preliminary result shows that the Xception model can classify one from different individuals with a 62% accuracy.

Joon Kuy Han, Hyoungshick Kim and Simon S. Woo
The 26th ACM Conference on Computer and Communications Security, London, UK, 2019
Many companies offer automatic speech recognition or Speech-to-Text APIs for use in diverse applications. However, audio classification algorithms trained with deep neural networks (DNNs) can sometimes misclassify adversarial examples, posing a significant threat to critical applications.
Keeyoung Kim, Byeongrak Seo, Sang-Hoon Rhee, Seungmoon Lee, and Simon S. Woo
CIKM'19, Beijing, China, Nov, 2019
Acceptance rate=21%, BK Computer Science IF=3
Manufacturing steel requires extremely challenging industrial processes. In particular, predicting the exact time instance of opening and closing tap-holes in a blast furnace has a great influence on steel production efficiency and operating cost, in addition to human safety.
Hyeonseong Jeon, Youngoh Bang, and Simon S. Woo
10th International Workshop on Human Behavior Understanding (HBU), held in conjunction with ICCV'19 Nov, 2019 - Seoul, S. Korea
Detecting realistic fake images and videos is an increasingly important and urgent problem because they can be maliciously used. In this work, we propose FakeTalkerDetect, which is based on siamese networks to detect the recently proposed realistic talking head with few-shot learning.
Youjin Shin, Sangyup Lee, Shahroz Tariq, and Simon S. Woo
Workshop on Tensor Methods for Emerging Data Science Challenges (TMEDSC), held in conjunction with KDD'19 Aug 5, 2019 - Anchorage, Alaska, USA

Jinwoo Cho, Shahroz Tariq, Sangyup Lee, Young Geun Kim, Jeong-Han Yun, Jonguk Kim, Hyoung Chun Kim and Simon S. Woo
5th Workshop on Mining and Learning from Time Series, held in conjunction with KDD'19 Aug 5, 2019 - Anchorage, Alaska, USA

Shahroz Tariq, Sangyup Lee, Youjin Shin, Myeong Shin Lee, Okchul Jung, Daewon Chung, and Simon S. Woo
ACM SIG KDD, Alaska, USA, 2019.
BK Computer Science IF=4
Detecting an anomaly is not only important for many terrestrial applications on Earth but also for space applications. Especially, satellite missions are highly risky because unexpected hardware and software failures can occur due to sudden or unforeseen space environment changes.

Yuri Son, Geumhwan Cho, Hyoungshick Kim and Simon S. Woo
ASIACCS: The 12th ACM Asia Conference on Computer and Communications Security, Auckland, New Zealand, 2019
BK Computer Science IF=1, Acceptance Rate = 22.5%
To understand users' risk perceptions about sharing their PHR on SNS, we first conducted a qualitative user study by interviewing 16 participants. Next, we conducted a large-scale online user study with 497 participants in the U.S. to validate our qualitative results from the first study.
Pratik Musale, Duin Baek, Nuwan Werellagama, Simon S. Woo, and and Bong Jun Choi
IEEE Access, Early Access, 2019
SCIE Q1 IF= 3.557
With a plethora of wearable IoT devices available today, we can easily monitor human activities, many of which are unconscious or subconscious. Interestingly, some of these activities exhibit distinct patterns for each individual, which can provide an opportunity to extract useful features for user authentication.
Youjin Shin and Simon S. Woo
The Web Conference (WWW), May 2019
BK Computer Science 우수학회 IF=3, Acceptance Rate 19.9%
In the past, there have been several studies in analyzing password strength and structures. However, there are still many unknown questions to understand what really makes passwords both memorable and strong. In this work, we aim to answer some of these questions by analyzing password dataset through the lenses of data science and machine learning perspectives.
Simon S. Woo, Le Xiao, Ron Artstein, Elsi Kaiser, and Jelena Mrikovic
ACM Transactions on Transactions on Privacy and Security (TOPS), January 2019
SCIE Q1 IF=2.1
Passwords are widely used for user authentication, but they are often difficult for a user to recall, easily cracked by automated programs, and heavily reused. Security questions are also used for secondary authentication. They are more memorable than passwords, because the question serves as a hint to the user, but they are very easily guessed. We propose a new authentication mechanism, called "life-experience passwords (LEPs)."
Shahroz Tariq, Sangyup Lee, Youjin Shin, Ho Young Kim, and Simon S. Woo
ACM SAC Cyprus April 2019
BK Computer Science 우수학회 IF=1, Acceptance Rate 25%
Creating fake images such as replacing one's face with other person's face has become much easier due to the advancement of sophisticated image editing tools. In addition, Generative Adversarial Networks (GANs) enable creating natural looking human faces. However, fake images can cause many potential problems, as they can be misused to abuse information, hurt people, and generate fake identification.

2018
Simon S. Woo
Elsevier Computers & Security, December 2018
SCIE Q1 IF=3.06
Most current 2D CAPTCHAs are vulnerable to automated character recognition attacks and the latest attacks can successfully break the 2D text CAPTCHAs at a rate of more than 90%. In this work, we present two novel 3D CAPTCHAs, which are more secure than current 2D text CAPTCHAs against automated character recognition attacks.
Joonkyu Han and Simon S. Woo
The 34th Annual Computer Security Applications Conference (ACSAC)
Puerto Rico, USA, 2018
Soyoon Jeon, Jihye Woo, Ji Won Choi, Hyoungshick Kim, and Simon S. Woo
Conference on Information Security and Cryptography 2017 Winter (CISC-W 2018) Seoul, Korea, 2018
Jihye Woo, Soyoon Jeon, Ji Won Choi, Hyoungshick Kim, and Simon S. Woo
Conference on Information Security and Cryptography 2017 Winter (CISC-W 2018) Seoul, Korea, 2018
H. Choi, J. Jeong,Simon S. Woo, K. Kang, and J. Hur
Elsevier Computers & Security, October 2018
SCIE Q1 IF=2.86
Honey encryption (HE) is a novel password-based encryption scheme that is secure against brute-force attacks even if users’ passwords have min-entropy. However, in HE, decryption with an incorrect key produces fake messages that appear valid. Hence, password typographical errors may confuse even legitimate users.
Yimin Zhu and Simon S. Woo
25th ACM Conference on Computer and Communications Security (CCS 2018), Toronto, USA, 2018
Machine learning algorithms including Deep Neural Networks (DNNs) have shown great success in many different areas. However, they are frequently susceptible to adversarial examples, which are maliciously crafted inputs to fool machine learning classifiers. On the other hand, humans cannot distinguish between non-adversarial and adversarial inputs.

Shahroz Tariq, Sangyup Lee, Huy Kang Kim, and Simon S. Woo
3rd International workshop on Information & Operational Technology (IT & OT) security systems (IOSec 2018), co-located with 21st International Symposium on Research in Attacks, Intrusions and Defenses (RAID 2018), Crete, Greece, Sept 2018
In vehicle communications, due to simplicity and reliability, a Controller Area Network (CAN) bus is used as the de facto standard to provide serial communication between Electronic Control Units (ECUs). However, prior research reveals that several network-level attacks can be performed on the CAN bus due to the lack of underlying security mechanism.

Shahroz Tariq, Sangyup Lee, Youjin Shin, Ho Young Kim, and Simon S. Woo
2nd International Workshop on Multimedia Privacy and Security (MPS 2018), co-located with 25th ACM Conference on Computer and Communications Security (CCS 2018), Toronto, USA, 2018
Due to the significant advancements in image processing and machine learning algorithms, it is much easier to create, edit, and produce high quality images. However, attackers can maliciously use these tools to create legitimate looking but fake images to harm others, bypass image detection algorithms, or fool image recognition classifiers.

Simon S. Woo and and Jelena Mirkovic
21st International Symposium on Research in Attacks, Intrusions and Defenses (RAID 2018), Crete, Greece, Sept 2018
BK우수학회 IF=2, Acceptance Rate 22.8%
Password meters and policies are currently the only tools helping users to create stronger passwords. However, such tools often do not provide consistent or useful feedback to users, and their suggestions may decrease memorability of resulting passwords.
Ameya Hanesamgar, Simon S. Woo, Chris Kanich, and Jelena Mirkovic
Usenix The Fourteenth Symposium on Usable Privacy and Security (SOUPS 2018), Baltimore, USA, 2018
It is no secret that users have difficulty choosing and remembering strong passwords, especially when asked to choose different passwords across different accounts. While research has shed light on password weaknesses and reuse, less is known about user motivations for following bad password practices.
Keeyoung Kim and Simon S. Woo
33rd IFIP TC-11 SEC 2018 International Conference on Information Security and Privacy Protection (IFIP-SEC), Poznan, Poland, Sept 2018
BK우수학회 IF=1, Acceptance Rate 36% , Best Student Paper Nominated
In recent years, significant advancements have been made in detecting and recognizing contents of images using Deep Neural Networks (DNNs). As a result, many companies offer image recognition APIs for use in diverse applications. However, image classification algorithms trained with DNNs can misclassify adversarial examples, posing a significant threat to critical applications.
Keeyoung Kim and Simon S. Woo
The Second International Workshop on The Bright and Dark Sides of Computer Vision: Challenges and Opportunities for Privacy and Security (CV-COPS2018) In conjunction with the IEEE CVPR 2018 , Salt Lake City, USA, June 2018
Jusop Choi, Taekkyung Oh, William Aiken, Simon S. Woo and Hyoungshick Kim
The 11th ACM Asia Conference on Computer and Communications Security (ACM ASIACCS), Incheon, Korea, 2018
A CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) provides the first line of defense to protect websites against bots and automatic crawling. Recently, audio-based CAPTCHA systems are started to use for visually impaired people in many internet services.
Simon S. Woo
A Short Workshop on Next Steps Towards Long Term Self Tracking at ACM SIG CHI2018, April, 2018, Montreal, Canada
We explore the benefit of a new long-term self-tracking application for the elderly population. In the last few years, there has been a significant increase in number of people dying alone or remaining undiscovered for a long period time in Korea and Japan.
Ameya Hanesamgar, Simon S. Woo, Chris Kanich, and Jelena Mirkovic
ACM SIG CHI2018, April, 2018, Montreal, Canada
BK우수학회 IF=4, Acceptance Rate 25.7%
It is no secret that users have difficulty choosing and remembering strong passwords, especially when asked to choose different passwords across different accounts. While research has shed light on password weaknesses and reuse, less is known about user motivations for following bad password practices.
Simon S. Woo, and Jelena Mirkovic
Review of KIISC (정보보호학회지), Feb. 2018
Passphrases are considered to be more secure than passwords since they are longer than passwords. However, users choose predictable word patterns and common phrases to make passphrases memorable, which in turn significantly lowers security.
Simon S. Woo, Kyeong Joo Jung, and Bong Jun Choi
Review of KIISC (정보보호학회지), Feb. 2018
Textual passwords are widely used for accessing online accounts. Despite the problems of current textual passwords, research has shown that there is no other strong alternatives for a textual password due to its simplicity.
2017
Pratik Musale, Duin Baek, Simon S. Woo, Bong Jun Choi
Proc. ACM CoNEXT, Seoul, South Korea, Dec. 2017. (Student Workshop)
Simon S. Woo, Wenzhi Li, and, Hyeran Jeon
Conference on Information Security and Cryptography 2017 Winter (CISC-W), Seoul, Korea, Dec. 2017 (Best paper (우수 논문상))
Simon S. Woo
The First International Workshop on The Bright and Dark Sides of Computer Vision: Challenges and Opportunities for Privacy and Security (CV-COPS2017) In conjunction with the IEEE CVPR 2017 , Honolulu, USA, July 2017
Simon S. Woo, Jelena Mirkovic, Ron Artstein, and Elsi Kaiser
Usenix The Thirteenteenth Symposium on Usable Privacy and Security (SOUPS 2017), Santa Clara, USA, July 2017
2016
Simon S. Woo and Jelena Mirkovic
Proceedings of the 10th International Conference on Passwords (Passwords), Bochum, Germany, 2016
Passphrases are regarded as more secure than passwords because they are longer than passwords. Yet, users use predictable word patterns and common phrases to make passphrases memorable, which in turn significantly lowers security.
Simon S. Woo, Jelena Mirkovic, Elsi Kaiser, and Ron Artstein
The 32nd Annual Computer Security Applications Conference (ACSAC), Los Angeles, 2016
BK우수학회 IF=2, Acceptance Rate 22.8%
Simon S. Woo, Zuyao Li, and Jelena Mirkovic
The 9th SIGGEN International Natural Language Generation Conference (INLG), Edinburgh, 2016
We explore a novel application of Question Generation (QG) for authentication use, where questions are widely used to verify user identity for online accounts. In our approach, we prompt users to provide a few sentences about their personal life events.
Simon S. Woo, Jingul Kim, Duoduo Yu, and Beomjun Kim
The 17th World Conference on Information Security Applications (WISA), Jeju, 2016
Best Conference Paper (우수논문상)
Most of current text-based CAPTCHAs have been shown to be easily breakable. In this work, we present two novel 3D CAPTCHA designs, which are more secure than current 2D text CAPTCHAs, against automated attacks. Our approach is to display CAPTCHA characters onto 3D objects to improve security.
2015
Simon S. Woo and Harsha Manjunatha
2nd ACM SIGIR Workshop on Privacy-Preserving Information Retrieval, Chilie, 2015
Jelena Mirkovic, Aimee Tabor, Simon S. Woo and Portia Pusey
USENIX Summit on Gaming, Games, and Gamification in Security Education (3GSE), D.C, 2015
Cybersecurity competitions are popular tools for attracting students to cybersecurity field. Yet, many competitions require extensive preparation, strong coding skills and solid background knowledge, not just in security, but also in system administration, networking and operating systems.
2014
Simon S. Woo and Jelena Mirkovic
Elsevier Computer Networks, February 2014.
SCIE Q1 IF=2.52
Cloud computing customers currently host all of their application components at a single cloud provider. Single-provider hosting eases maintenance tasks, but reduces resilience to failures. Recent research (Li et al., 2010) also shows that providers’ offers differ greatly in performance and price, and no single provider is the best in all service categories.
Simon S. Woo, Jelena Mikovic, Ron Artstein, and Elsi Kaiser
Who are you?! Adventures in Authentication: ACM SOUPS-WAY Workshop, 2014, Menlo Park, CA
Passwords are widely used for user authentication, but they are often difficult for a user to recall, easily cracked by automated programs and heavily reused. Security questions are also used for secondary authentication. They are more memorable than passwords, but are very easily guessed. We propose a new authentication mechanism, called "life-experience passwords (LEPs)," which outperforms passwords and security questions, both at recall and at security.
Simon S. Woo, and B. Kim
Information Sciences Institute Graduate Student Symposium (ISI-GSS), Nov, 2014 (Best Student Paper)
Current 2D CAPTCHA mechanisms can be easily defeated by character recognition and segmentation attacks by automated machines. Recently, 3D CAPTCHA schemes have been proposed to overcome the weaknesses of 2D CAPTCHA for a few websites.
Simon S. Woo, and B. Kim
23rd International World Wide Web (WWW) Conference, 2014
Current 2D CAPTCHA mechanisms can be easily defeated by character recognition and segmentation attacks by automated machines. Recently, 3D CAPTCHA schemes have been proposed to overcome the weaknesses of 2D CAPTCHA for a few websites.
Simon S. Woo, Jelena Mirkovic, and Elsi Kaiser
Network and Distributed System Security (NDSS) Symposium, Feb, 2014
2011
Simon S. Woo*
IEEE Globecom 2011, Houston, TX
Acceptance rate: 36%
To synchronize clocks between spacecraft in proximity, the Proximity-1 Space Link Interleaved Time Synchronization (PITS) Protocol has been proposed. PITS is based on the NTP Interleaved On-Wire Protocol and is capable of being adapted and integrated into CCSDS Proximity-1 Space Link with minimal modifications.
2010
E. Jennings, J. Segui, and Simon S. Woo
AIAA SpaceOps 2010, Huntsville, AL
Space Exploration missions requires the design and implementation of space networking that differs from terrestrial networks. In a space networking architecture, interplanetary communication protocols need to be designed, validated and evaluated carefully to support different mission requirements.
Simon S. Woo, David Mills, and J. Gao
AIAA SpaceOps 2010 (Invited for Book Chapter)
Time distribution and synchronization in deep space network are challenging due to long propagation delays, spacecraft movements, and relativistic effects. Further, the Network Time Protocol (NTP) designed for terrestrial networks may not work properly in space
2009
E. Jennings, R. Borgen, C. Chevalier, E. Wesley, Sam Nguyen, John Segui, Tudor Stoenescu, Shin-Ywan Wang, and Simon S. Woo
AIAA, Modeling and Simulation Technologies (AIAA MST) Conference, 2009
In this work, we focus on the development of a simulation tool to assist in analysis of current and future (proposed) network architectures for NASA. Specifically, the Space Communications and Navigation (SCaN) Network is being architected as an integrated set of new assets and a federation of upgraded legacy systems. The SCaN architecture for the initial missions for returning humans to the moon and beyond will include the Space Network (SN) and the Near-Earth Network (NEN).
Simon S. Woo and Tudor Stoenescu
IEEE 69th Vehicular Technology Conference (IEEE VTC) 2009-Spring, Barcelona, Spain, April, 2009
In this work, we consider information dissemination and sharing in a highly dynamic peer-to-peer (P2P) communication network. In particular, we explore a network coding technique for transmission and a rank based peer selection (RBPS) method for network formation.
2008
Esther H. Jennings, Sam P. Nguyen, Shin-Ywan Wang, and Simon S. Woo
AIAA SpaceOps 2008
NASA’s planned Lunar missions will involve multiple NASA centers where each participating center has a specific role and specialization. In this vision, the Constellation program (CxP)’s Distributed System Integration Laboratories (DSIL) architecture consist of multiple System Integration Labs (SILs), with simulators, emulators, testlabs and control centers interacting with each other over a broadband network to perform test and verification for mission scenarios.
Simon S. Woo and Mike Cheng
IEEE Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, March 2008.
It is common in data transmissions that some information is more important than others. This is especially true in space communications where mission critical information or science data are high priority. In this work, we propose a simple yet constructive scheme to send high priority data reliably and efficiently using Luby transform (LT) codes.
Simon S. Woo, Esther Jennings, and Loren Clare
IEEE Aerospace Conference, Big Sky, MT, March, 2008
Advances in technology have made the large-scale deployment of low-cost networked sensors possible for situational awareness. We developed a Simulation Tool for the Advanced Sensors Collaborative Technology Alliance (ASCTA) Microsensor Network Architecture (STAMINA) to evaluate the performance of networked sensor systems.
2007
Mike Cheng, Simon S. Woo, Kar-Ming Cheung, Sam Dolinar, and Jon Hamkins
Research and Technology Development Poster session, (R&TD), Pasadena, Nov, 2007
2006
Simon S. Woo and Jay Gao
AIAA SpaceOps 2006, Rome, Italy
This study presents an analysis of the delay performance of the CCSDS File Delivery Protocol (CFDP) over weather-dependent Ka-band channel. The Ka-band channel condition is determined by the strength of the atmospheric noise temperature, which is weather dependent.